Datablist Data Extractor is a perfect tool to extract structured information from unstructured text.
For data cleaning, the Data Extractor helps you find entities in your CSV texts. When dealing with scraped data, this tool finds URLs and email addresses in scraped text to build your lead list.
The data extractor uses pattern recognition to find:
- Email Addresses in texts
- URLs in texts
- Domains from email addresses
- Domains from URLs
- Mentions (ex: @name) in texts
- Tags (ex: #tag) in texts
How to use the Data Extractor
Step 1: Open the Data Extractor
The Data Extractor tool works by selecting the items to process in this order:
- If you have selected items in your collection, it will process them
- If you have a filter or a full-text search term, it will process the filtered items
- Otherwise, it will process all your collection items
Datablist Data Extractor is available from the "Edit" menu. Just click on the "Extract url, email, tag, etc." menu item.
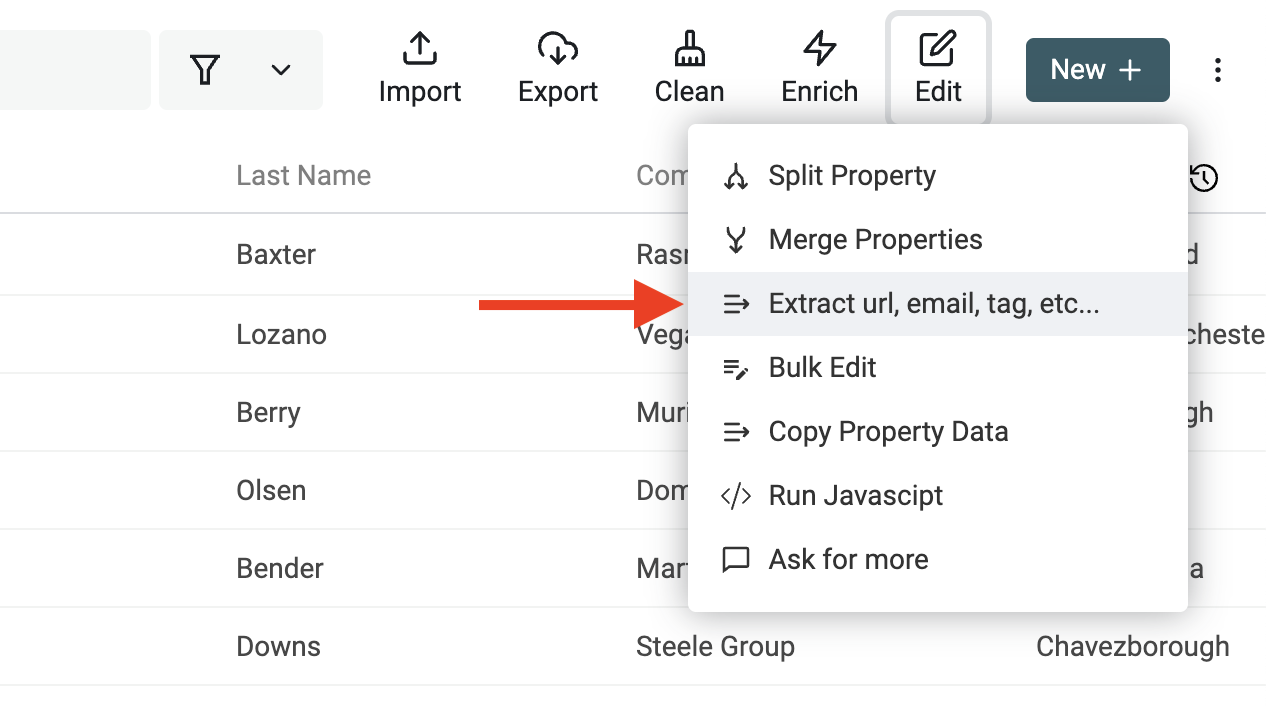
Step 2: Select a property with unstructured text
Then, select the property from your collection you want to extract data from.
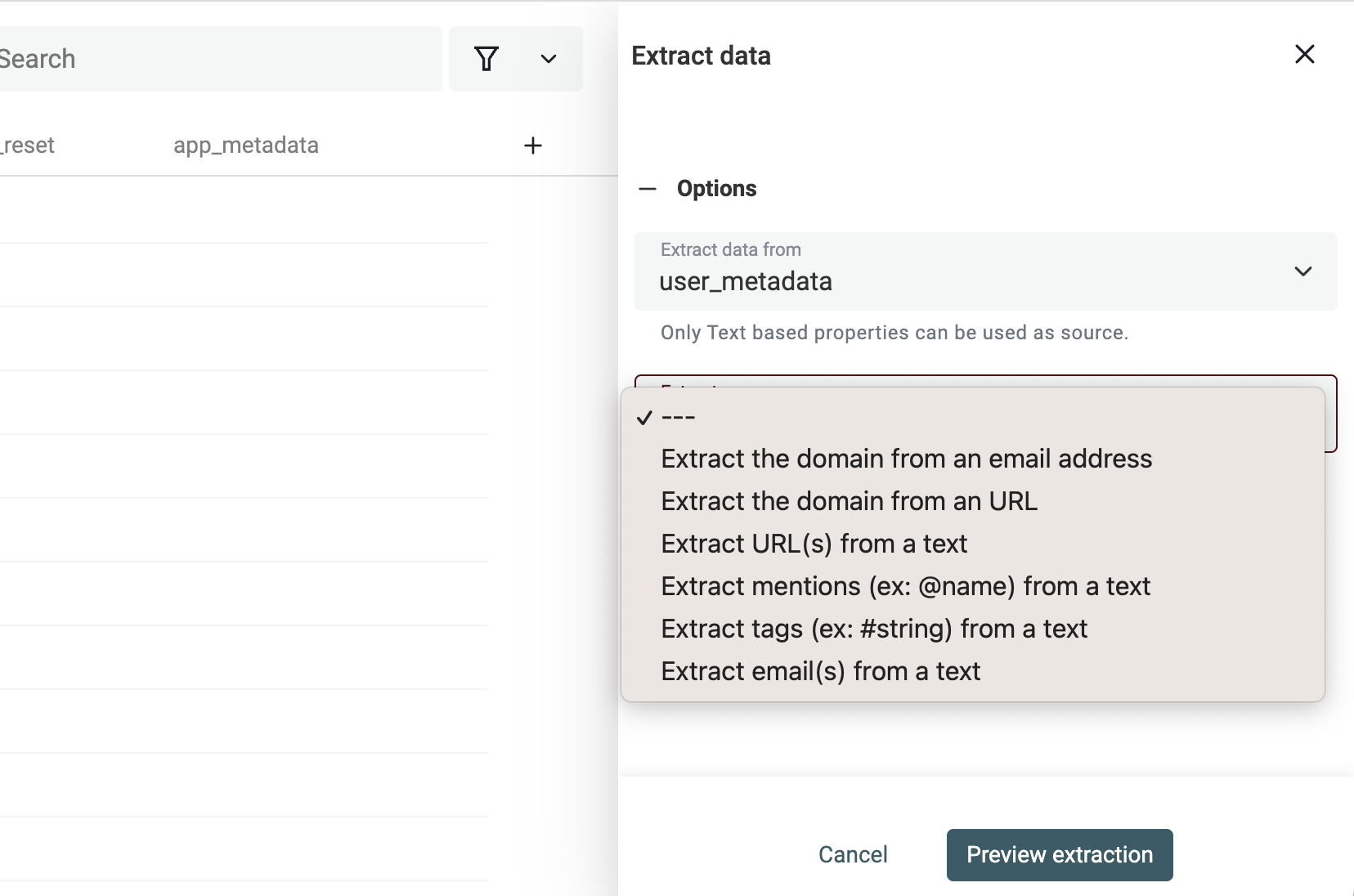
Step 2: Run the Data Extractor
A dry run lets you get a preview of the extraction on the first 10 items.
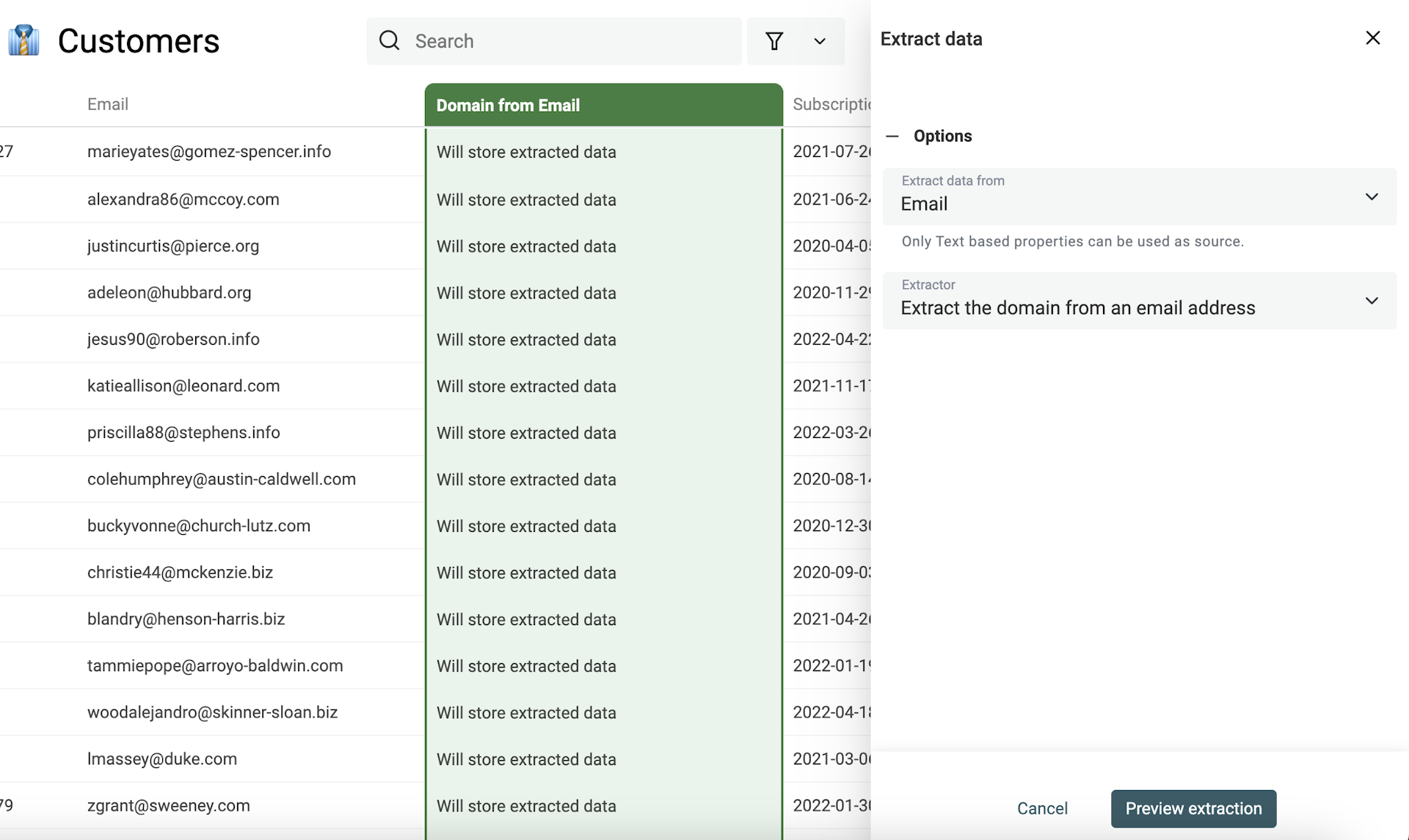
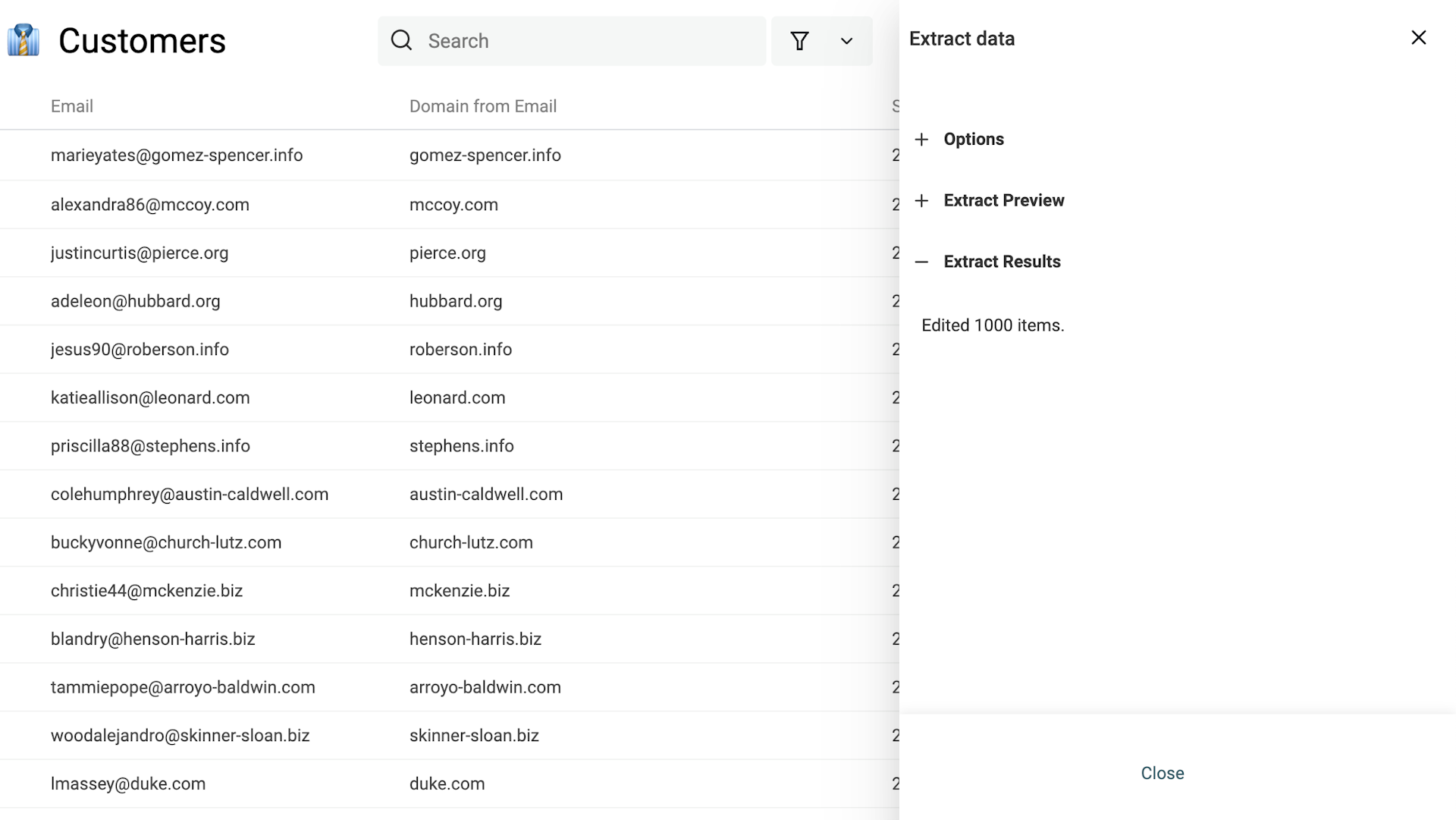
If the preview results suit you, click on the "Extract data" to process your items.
Notes: The dry run step is reinitialized each time the data extractor options change.
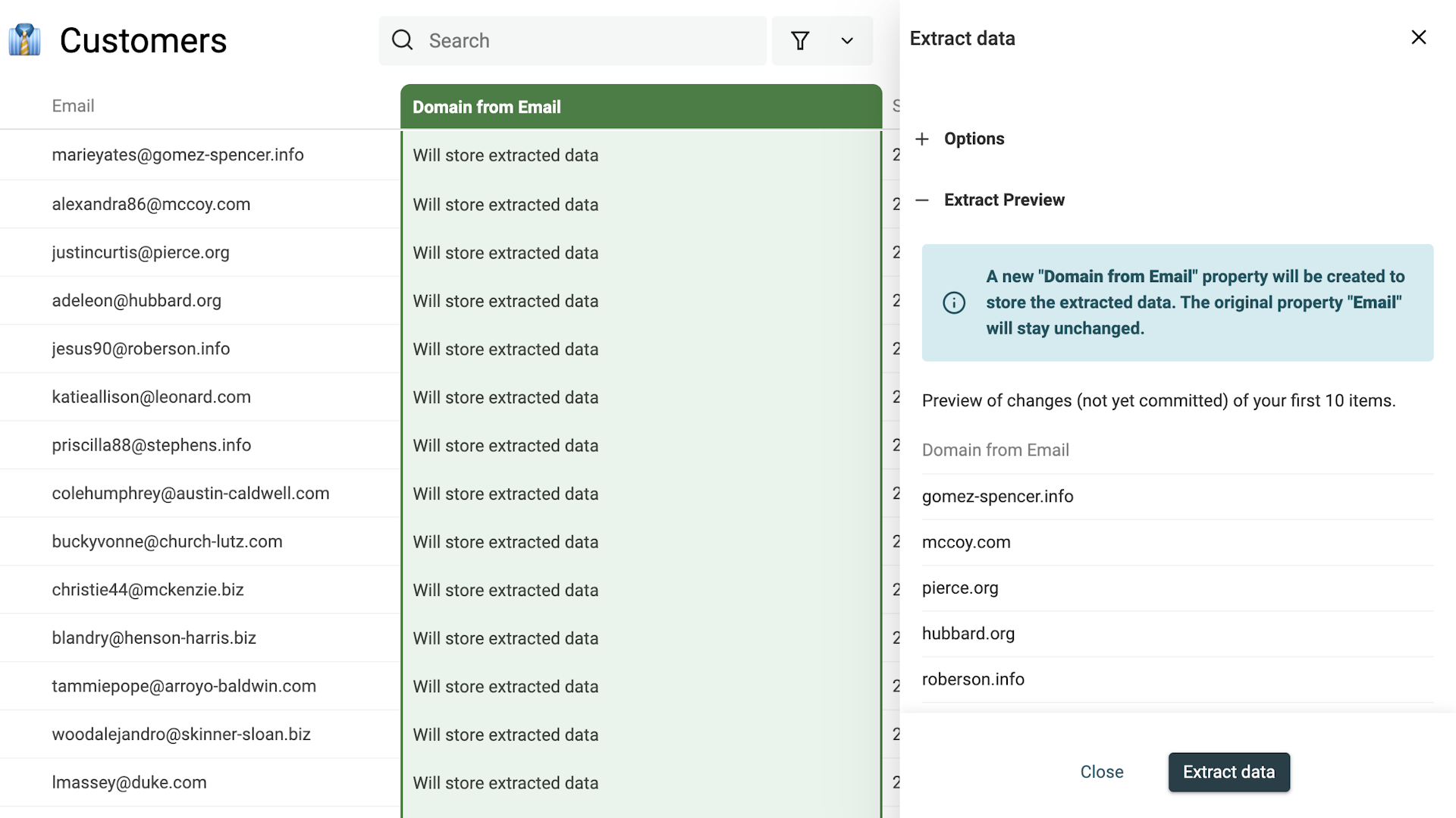
Once finished, a summary is displayed with the number of items processed. And your data table is updated with the results.
Dealing with multiple results
When multiple entities are found in your text, the Data Extractor returns all the entities separated with a comma.
Extractor descriptions
Extract the domain from an email address
This extractor takes a property with email addresses and returns the domain with the extension.
Examples:
- contact@datablist.com -> datablist.com
- jean.bond@gmail.uk.co -> jean.bond@gmail.uk.co
Note: If the email address is invalid, it returns an empty value.
Extract email addresses from a text
This extractor parses a text property to find one or several email addresses.
For example, from a text such as:
Please contact us at name@gmail.com for any inquiries about XXX.
Or use the following email address for customer support questions: support@xxx.com
The extractor returns: name@gmail.com,support@xxx.com
Extract URLs from a text
This extractor parses a text property to find one or several URLs.
For example, from a text such as:
Visit our online documentation at https://docs.datablist.com
The extractor returns: https://docs.datablist.com
Note: To be valid, the URLs must be absolute, with scheme (https, http, or ftp, etc). A partial URL like
doc.datablist.comwon't be returned.
Extract the domain from a URL
This extractor takes a property with an URL and returns the domain with the extension.
Examples:
- https://www.datablist.com -> datablist.com
- https://www.google.io/test/path/string.html -> google.io
Note: If the URL is invalid, it returns an empty value.
Extract mentions from a text
This extractor parses a text and returns the mentions in it. The @ character is also returned.
Examples:
Mum, friend with @pseudo and married with @pseudo2
Returns @pseudo,@pseudo2
Extract tags from a text
This extractor parses a text and returns the tags in it. The # character is also returned.
Examples:
Live in #paris. #workhardplayhard
Returns #paris,#workhardplayhard