

Data cleaning (cleansing) is no longer restricted to data analysts. If you are dealing with a list of prospects, if you use scraped data in your processes, or if you consolidate multiple source of data, you know the importance of effective data cleaning.
Google Sheets and Excel are enough for simple operations but are limited when it comes to consolidation and deduplication.
In this guide, you will learn how to use Datablist, a free online tool to clean and normalize your data.
Here is a quick summary of the clean-up operations found in this article:
- Convert text to Datetime, Number, Boolean
- Convert HTML to text (remove HTML tags)
- Remove extra spaces from texts
- Normalize your data
- Remove symbols from texts
- Split full name into First Name and Last Name
- Deduplicate items
- Extract email addresses, URLs, etc. from texts
- Use Regular Expressions to filter and validate data
- Write custom transformations with JavaScript code
- Validate Email Addresses
Import from CSV or copy-paste data
Datablist is a perfect tool for cleaning data. It's an online CSV editor with cleaning, bulk editing, and enrichment features. And it scales up to millions of items per collection.
Open Datablist, and load your data sources collections.
To create a new collection, click on the + button in the sidebar. And click "Import CSV/Excel" to load your file. Or click the shortcut from the getting started page to move directly to the file import step.

Auto detect format
Datablist import assistant detects automatically email addresses, Datetimes in ISO 8601, Booleans, Numbers, URLs, etc. when they are well formated.
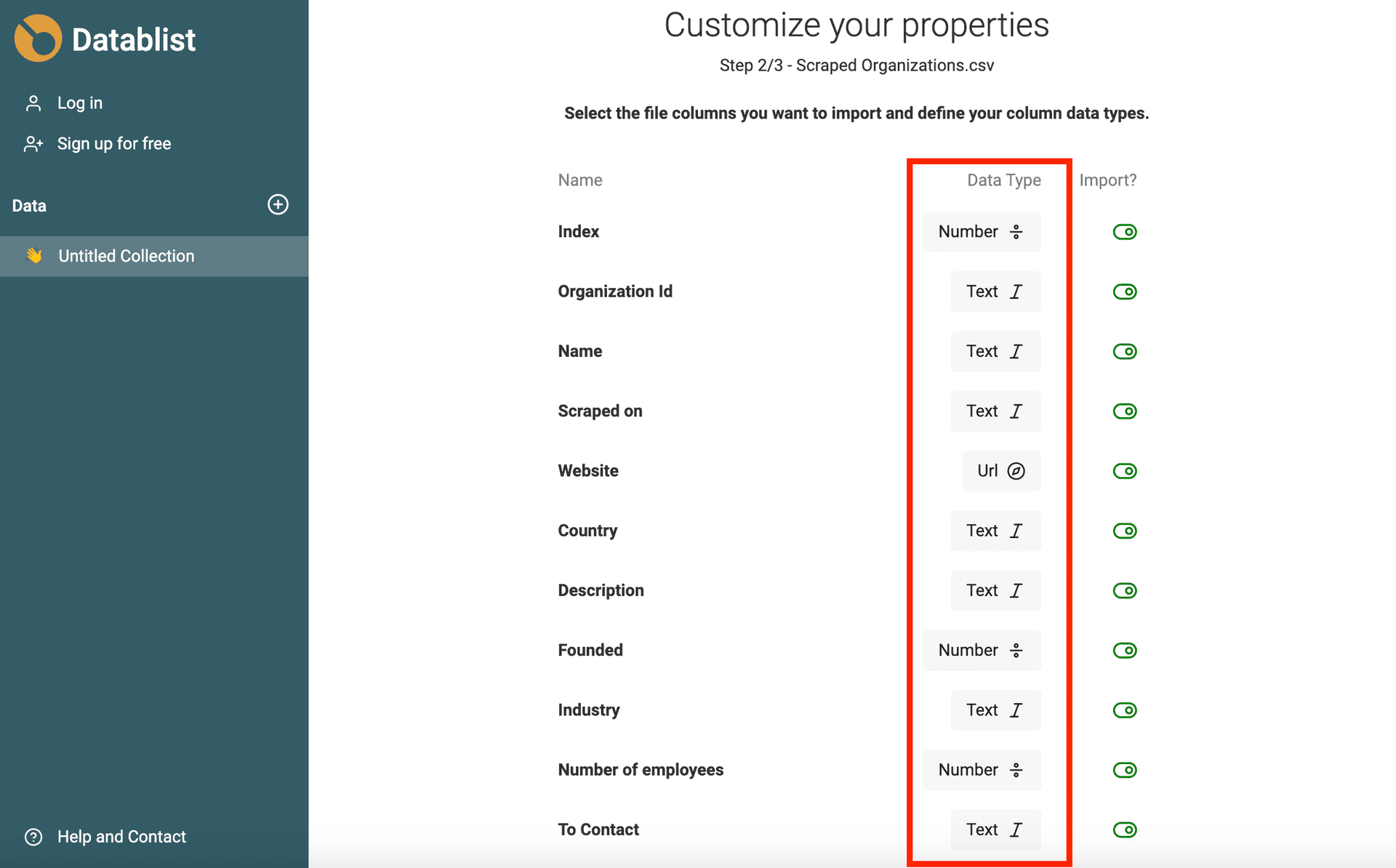
If your data required more complex analysis (different datetime format, typos in URL or email address), import them as Text property. I'll show you in the next section how to convert your text properties to Datetime, Boolean, or Number.
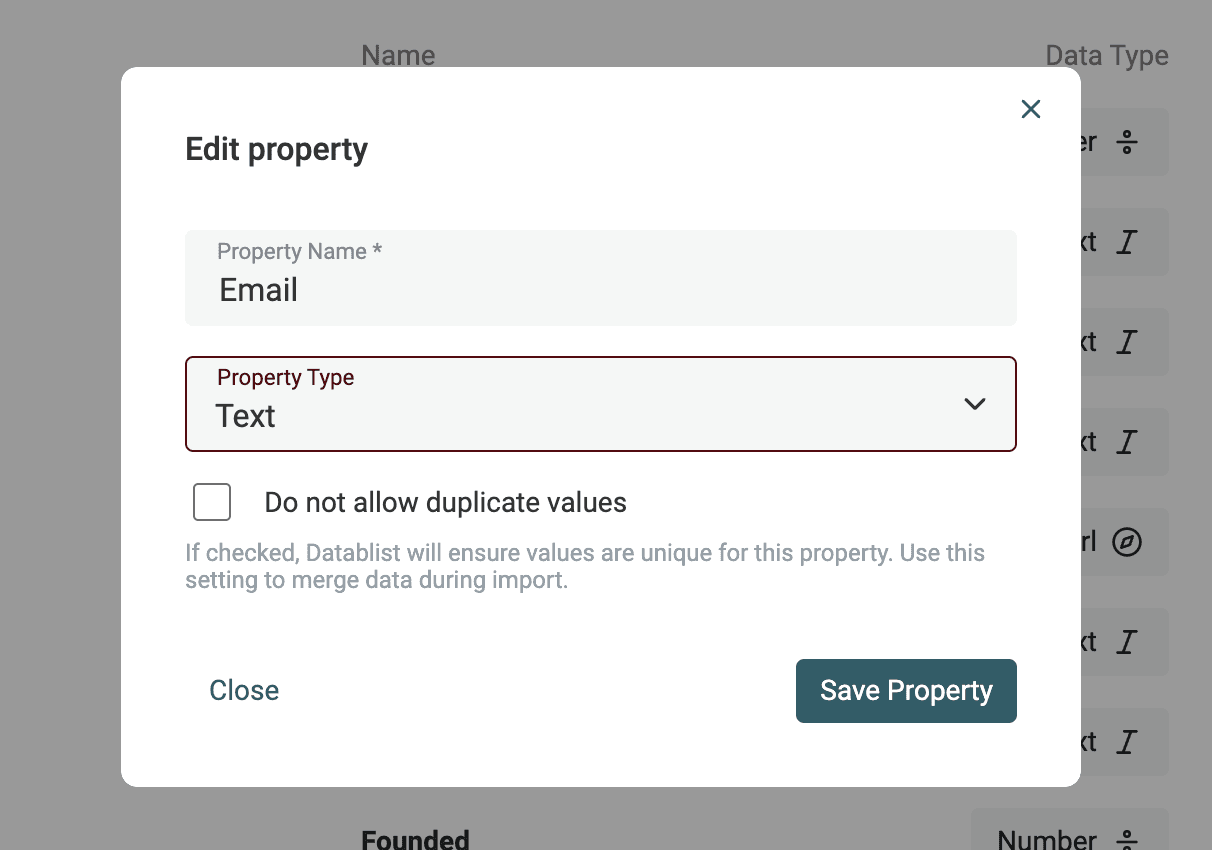
Convert text to datetime, boolean, number
Marie Kondo says "Life truly begins after you have put your house in order". Same with your data: "Sales truly begins after you have put your data in order"! 😅
Filtering on a date (creation date, funding date, etc.), a number (price, number of employees), or a boolean is so much easier when they are native objects and not just text.
Open the "Text to Datetime, Number, Checkbox" tool from the "Clean" menu.

Convert any text to Datetime format
Datetime has an international format called ISO 8601 with a defined structure. If your data uses the ISO 8601 format, a Datetime property will be created automatically during import to store the data.
For Date and Datetime values in other formats, you have to specify the format used so Datablist can convert it to structured Datetime values.
Select the property to convert and select "Convert to Datetime".
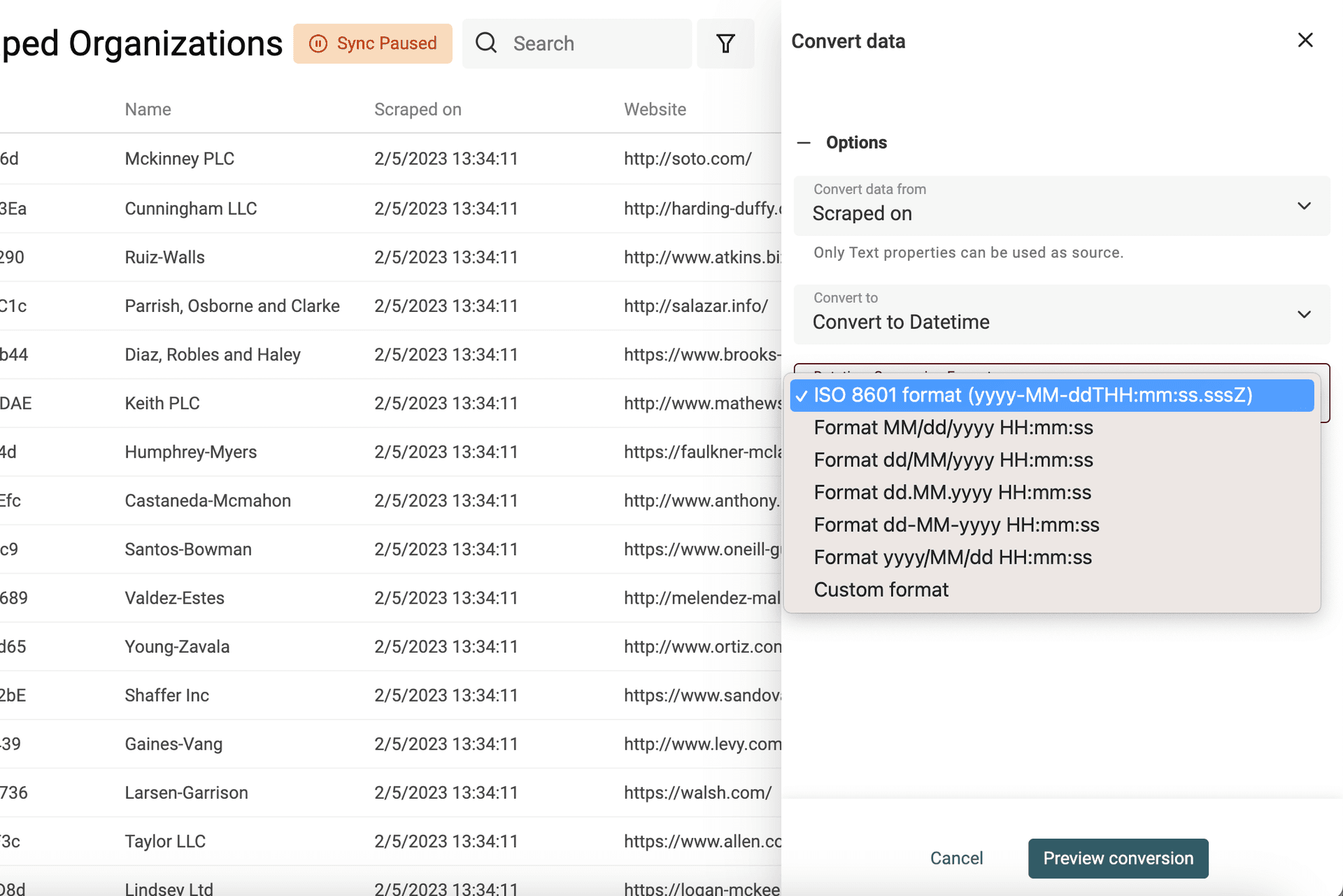
Common formats are listed (datetime formats used by Google Sheets and Excel) or select "Custom format" to define your datetime format.

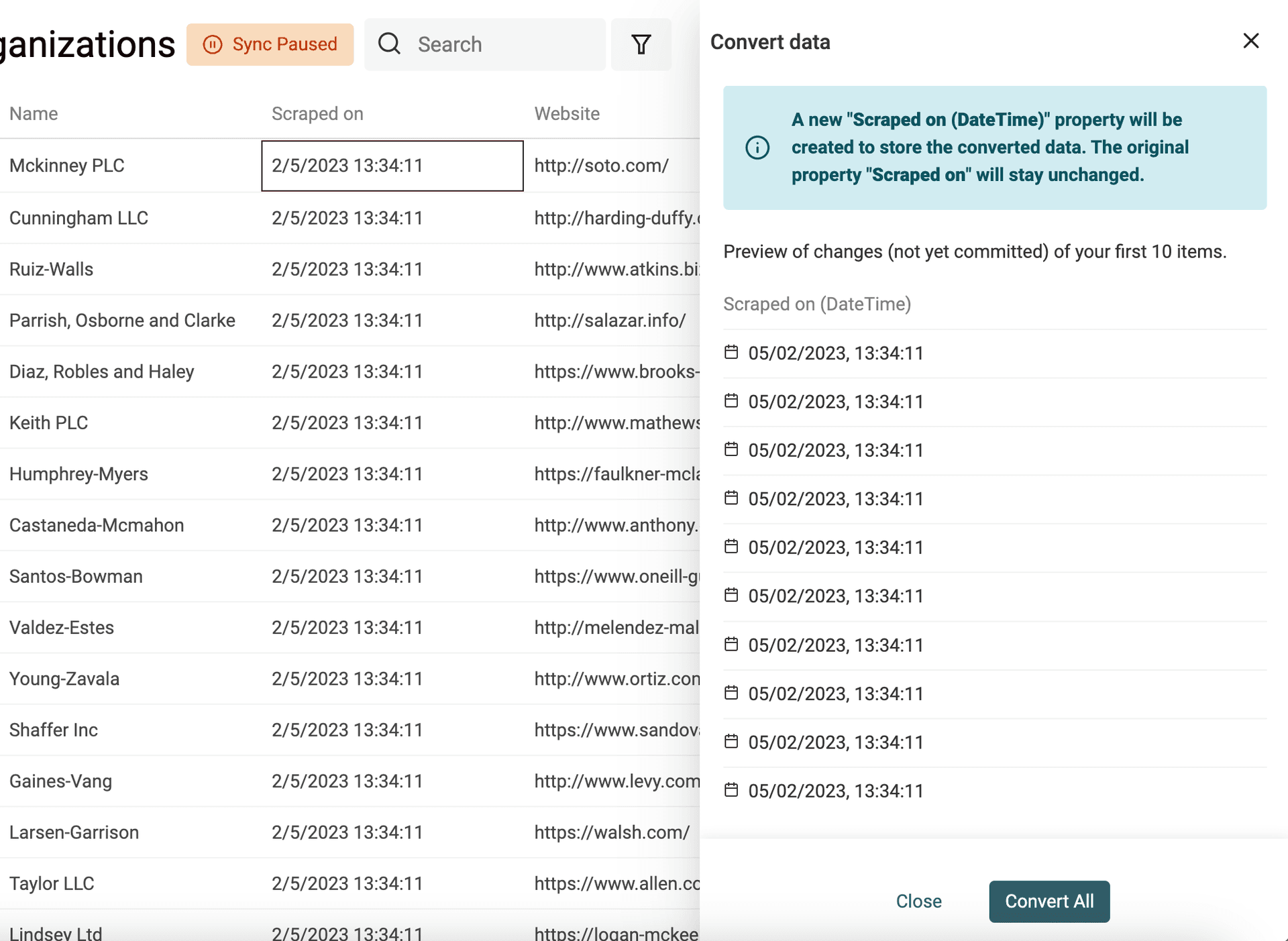
If you have dates and/or datetimes in several formats for a single property, select "Custom or multiple formats" in the "Datetime Conversion Format". Then enter on format per line. Datablist will try each format starting from the first line until it returns a valid Date.
👉 Visit our documentation to learn more on custom datetime formats.
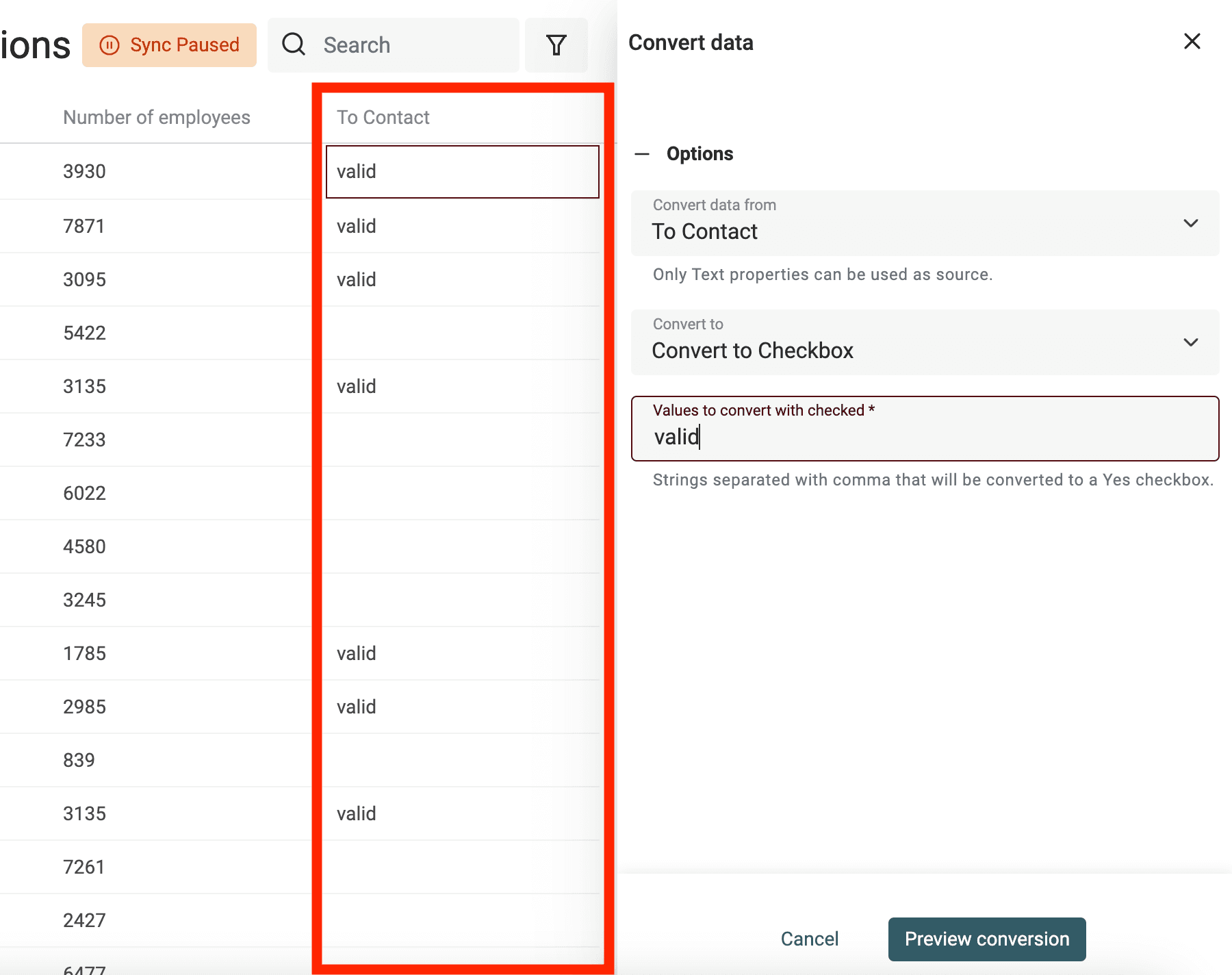
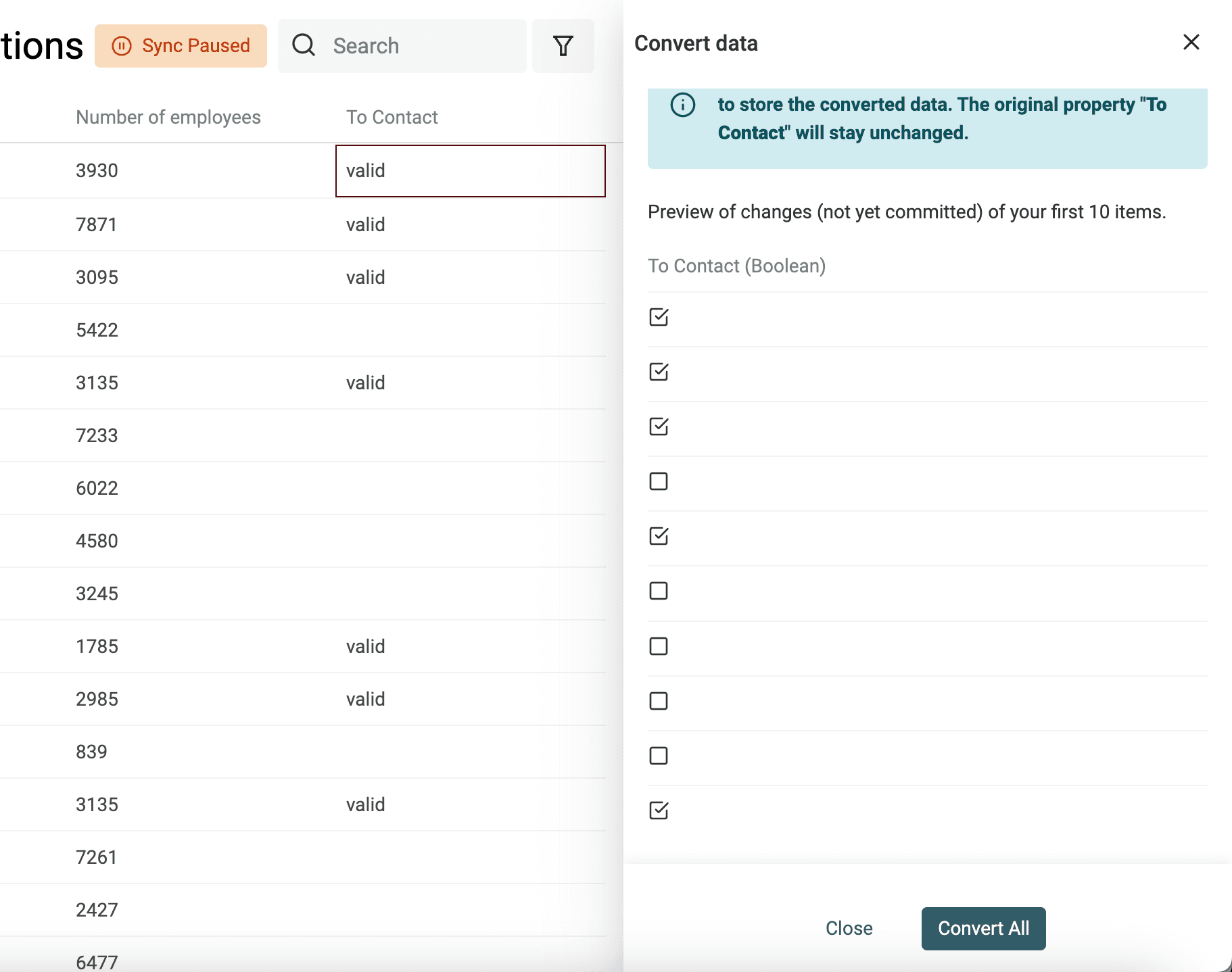
Create Checkboxes (Boolean) from text values
Datablist converts automatically columns with "Yes, No", "TRUE, FALSE", etc. to Checkbox properties on import. Use the converter for more complex conversions.
Define the values (separated with commas) that will be converted to a checked checkbox. Other values will be kept unchecked.
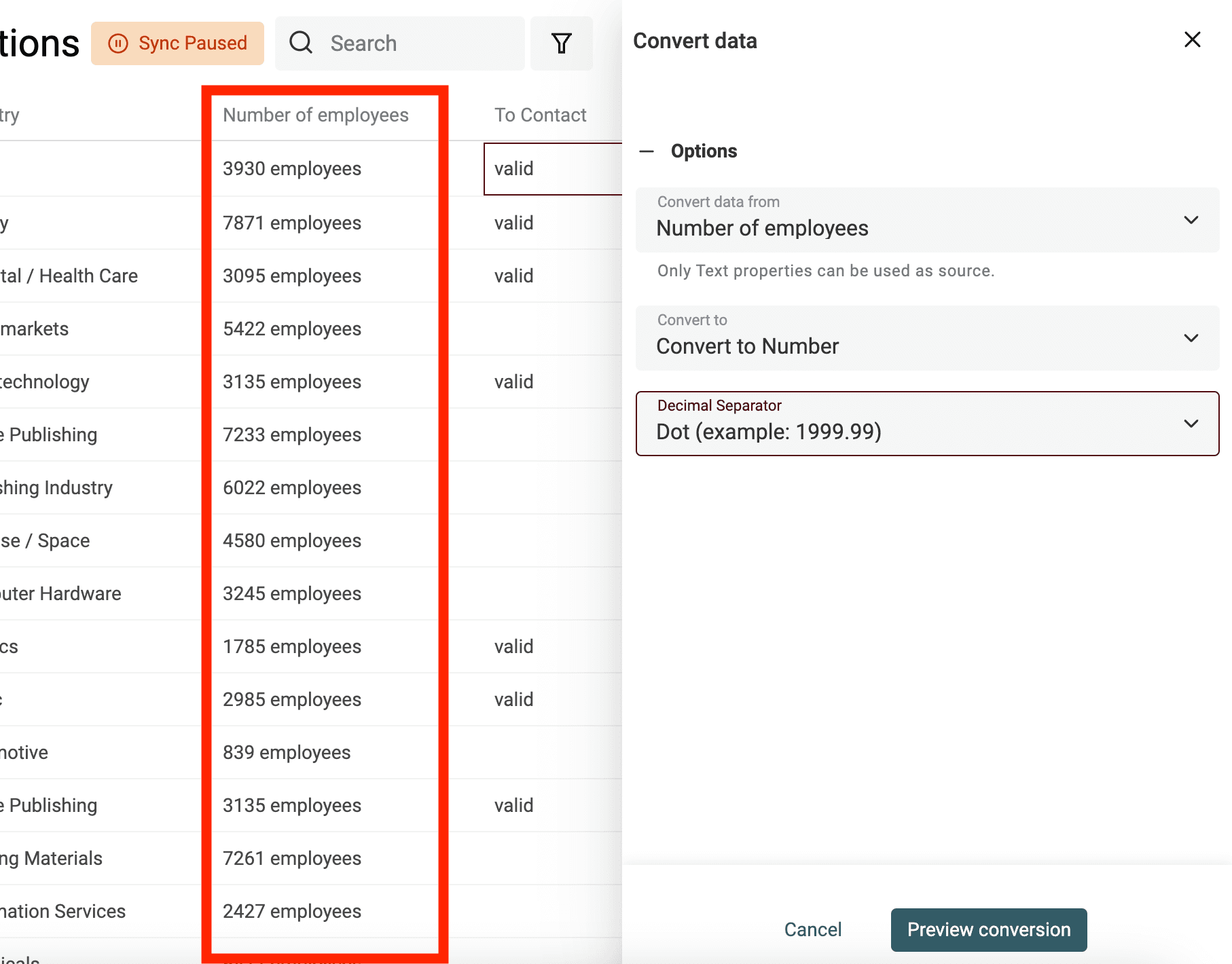
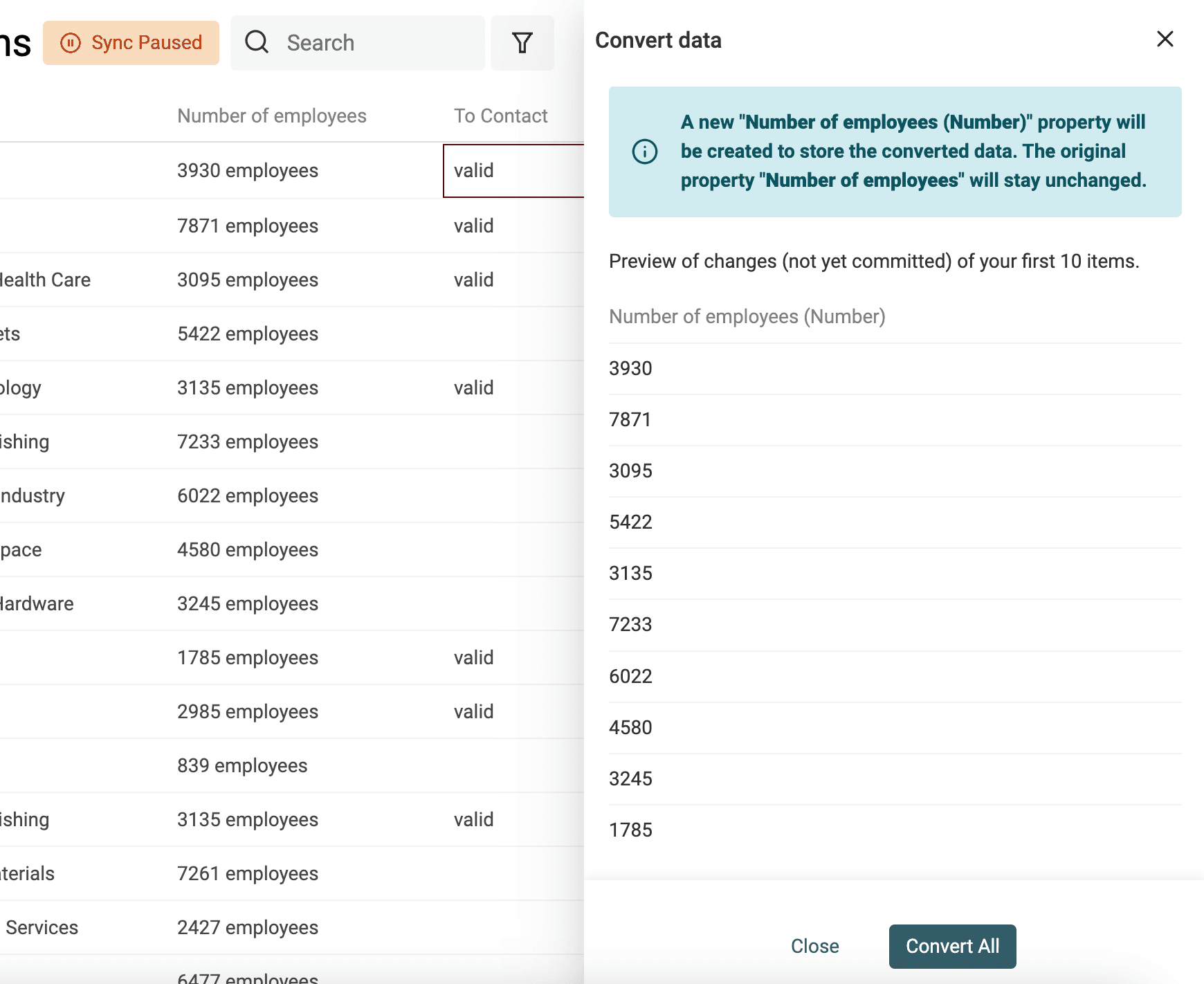
Extract number values from texts
Use the "Text to number" converter to:
- Normalize numbers with custom decimal and thousand separators
- Extract numbers from texts with letters
👉 Visit our documentation to learn more on number conversion.
Clean data
Convert HTML to text
Scraping tools parse HTML code and you may get HTML tags in your texts.
HTML codes have links, images, and lists with bullet points. And are written with paragraphs and multi-lines.
The goal is to keep some of the order HTML brings but transform a non-readable code into plaintext.
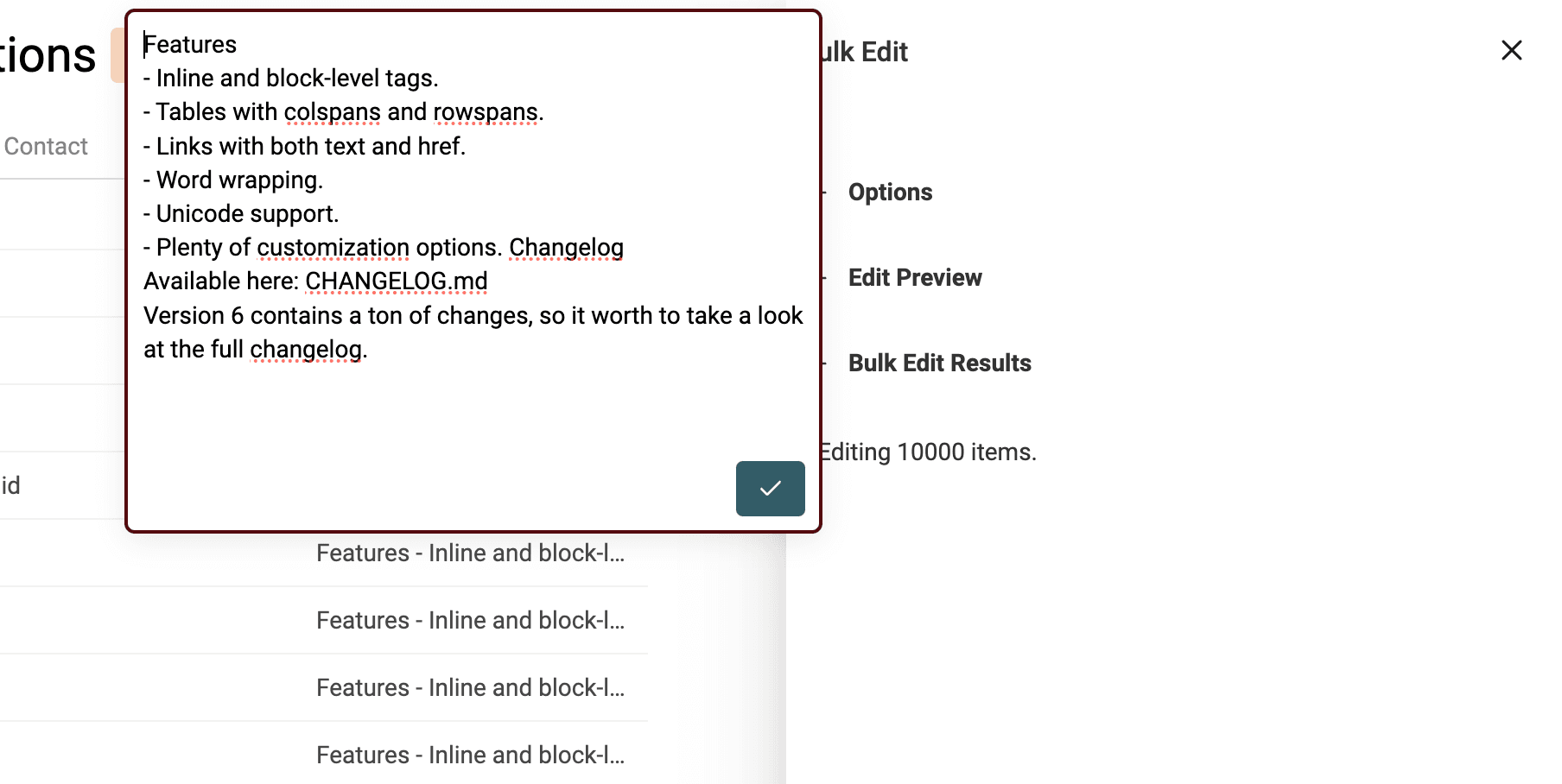
Datablist HTML to Text converter keeps newlines, and transforms bullet points into list prefixed with -.
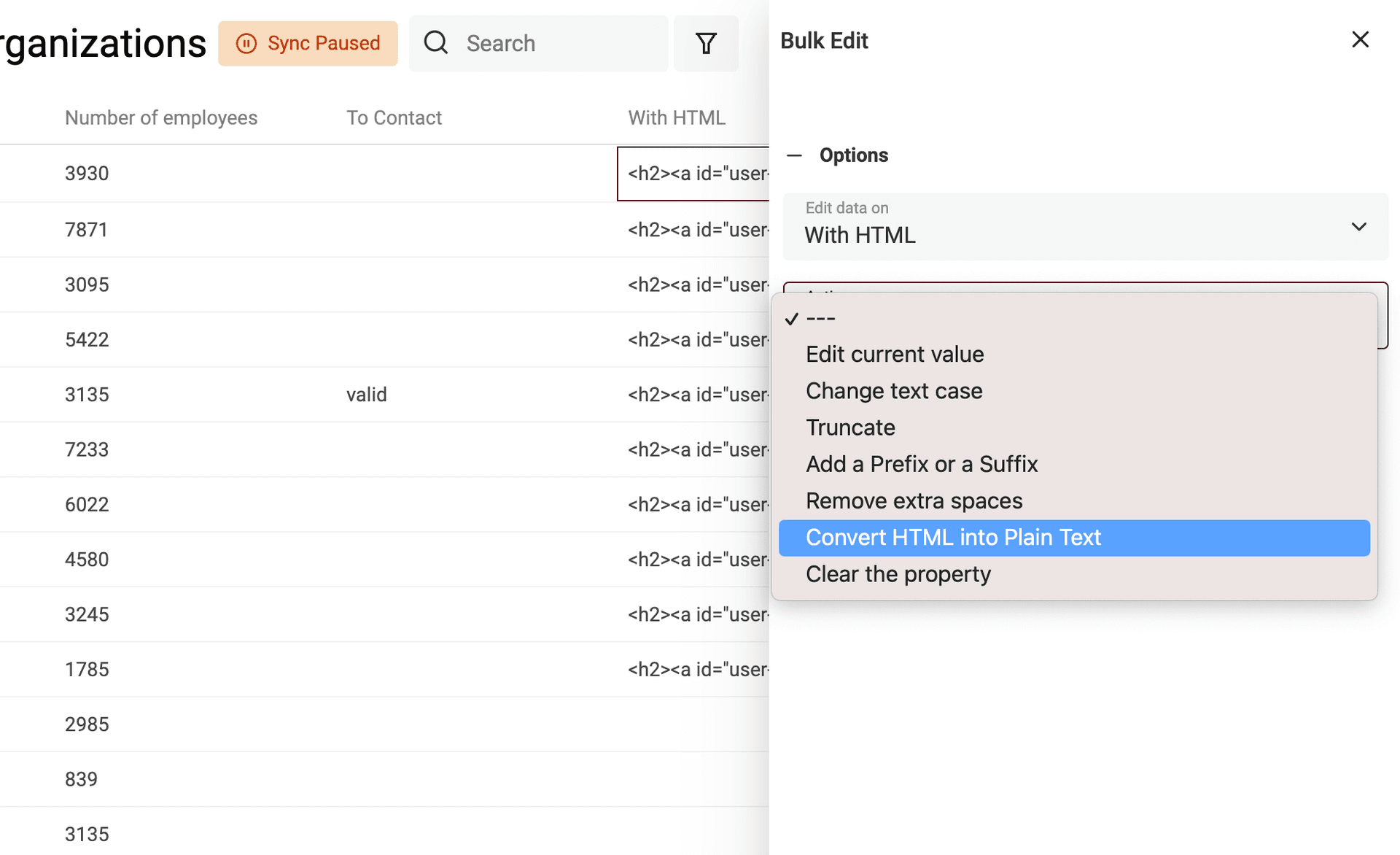
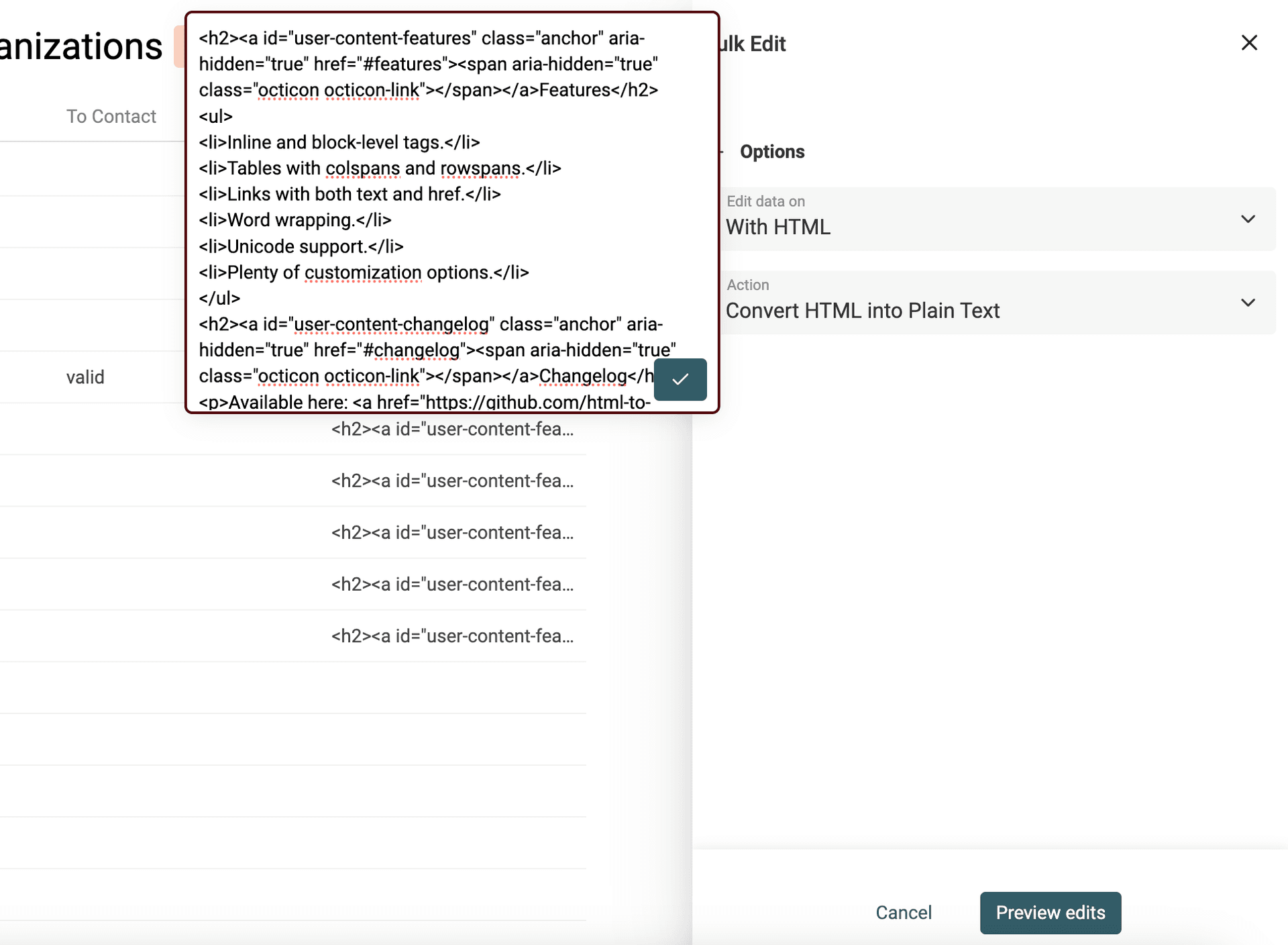
To transform your text with HTML tags into plaintext, open the Bulk Edit tool in the Edit menu.

Select your property with HTML tags. And select "Convert HTML into plain text".
Remove extra spaces
Another common issue with messy data is extra spaces. Spaces come from new lines, from Tab, and other characters that represent a space in HTML.
Datablist comes with a cleaning tool to get rid of extra spaces.
It has two modes:
- Mode 1: Remove all spaces - This mode remove any space characters. This is good to clean phone number, price, etc. where you need to have only letters, digits, etc.
- Mode 2: Remove only "extra spaces".
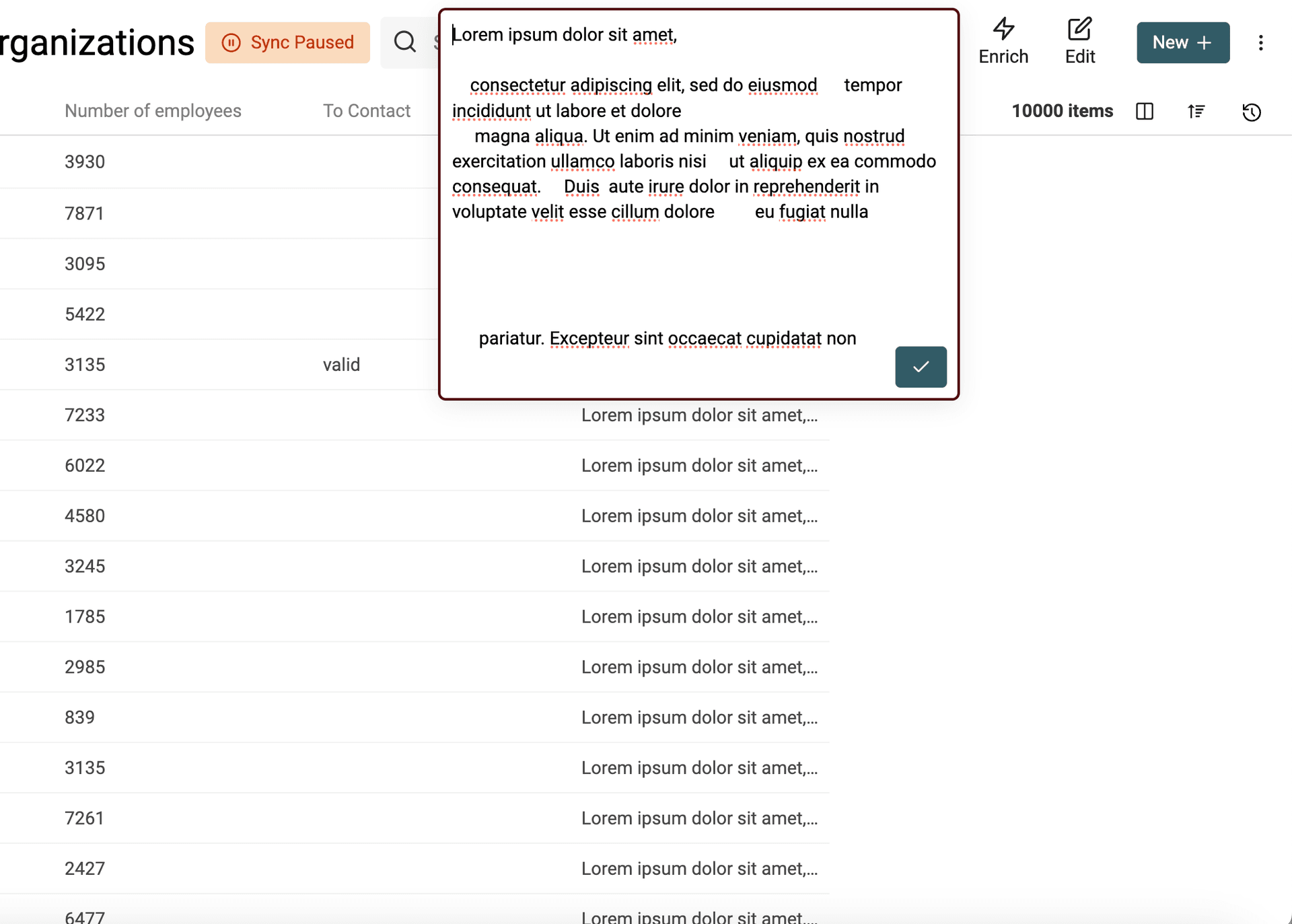
For the second mode, the algorithm works as follow:
- It removes extra spaces between words
- It removes empty lines
- It removes leading and trailing spaces on each line
To remove extra spaces, go on the "Bulk Edit" tool from the "Edit" menu. Select your property and the "Remove extra spaces" action.
Check the "Remove all spaces" option to get rid of all spaces characters. Keep it disabled to only remove "extra spaces".

Here is an example with the algorithm removing extra spaces:
After the cleaning, without the extra spaces:
Clean text case
Changing the case of your text is simple. Open the "Bulk Edit" tool in the "Edit" menu.
Select the property to process and use the "Change text case" action.

3 modes are available:
- Uppercase - All letters will be converted to their uppercase version. Ex:
john=>JOHN - Lowercase - All letters will be converted to their lowercase version. Ex:
API=>api - Capitalize - The first letter of all words will be capitalized. Ex:
john is a good man=>John Is A Good Man - Capitalize only the first word - Only the first letter of the first word will be capitalized. Ex:
john is a good man=>John is a good man
Remove symbols from texts
Texts scrapped from HTML pages, or with user inputs (for example LinkedIn profile titles) can contain text symbols: smiley, and other characters that will impact the processing of your data. A simple smiley at the end of a name can prevent it from being spotted by a deduplication algorithm.
Datablist has a built-in processor to remove any non-text symbols from your data.
Click on "Bulk Edit" from the "Edit" menu, select a text property and, pick the "Remove symbols" transformation.

If the preview is good, run the transformation to process your items.

Normalization with Find and Replace
To build segments on your prospect lists, you must normalize your data.
- Normalize job titles
- Normalize countries, cities
- Normalize URL
- Etc.
Your goal is to reduce a property with free text into a property with limited choices. Or to transform your texts into a more basic version (URL with paths into a simple URL domain).
Datablist comes with a powerful Find and Replace tool. It works with simple text and with regular expressions.
Regular Expressions are both complex and very powerful.
Here are some examples of how to use RegEx to clean your data.
Remove query params from an URL
Scraped URLs have useless query parameters for tracking or marketing reasons. Removing them from your URLs will give you clean URLs. And it will help you deal with deduplication by using the URL to find duplicate items.
To remove query parameters from your URLs, check the "Match using regular expression" option. And use the following regular expression with an empty replacement text:
\?.*$
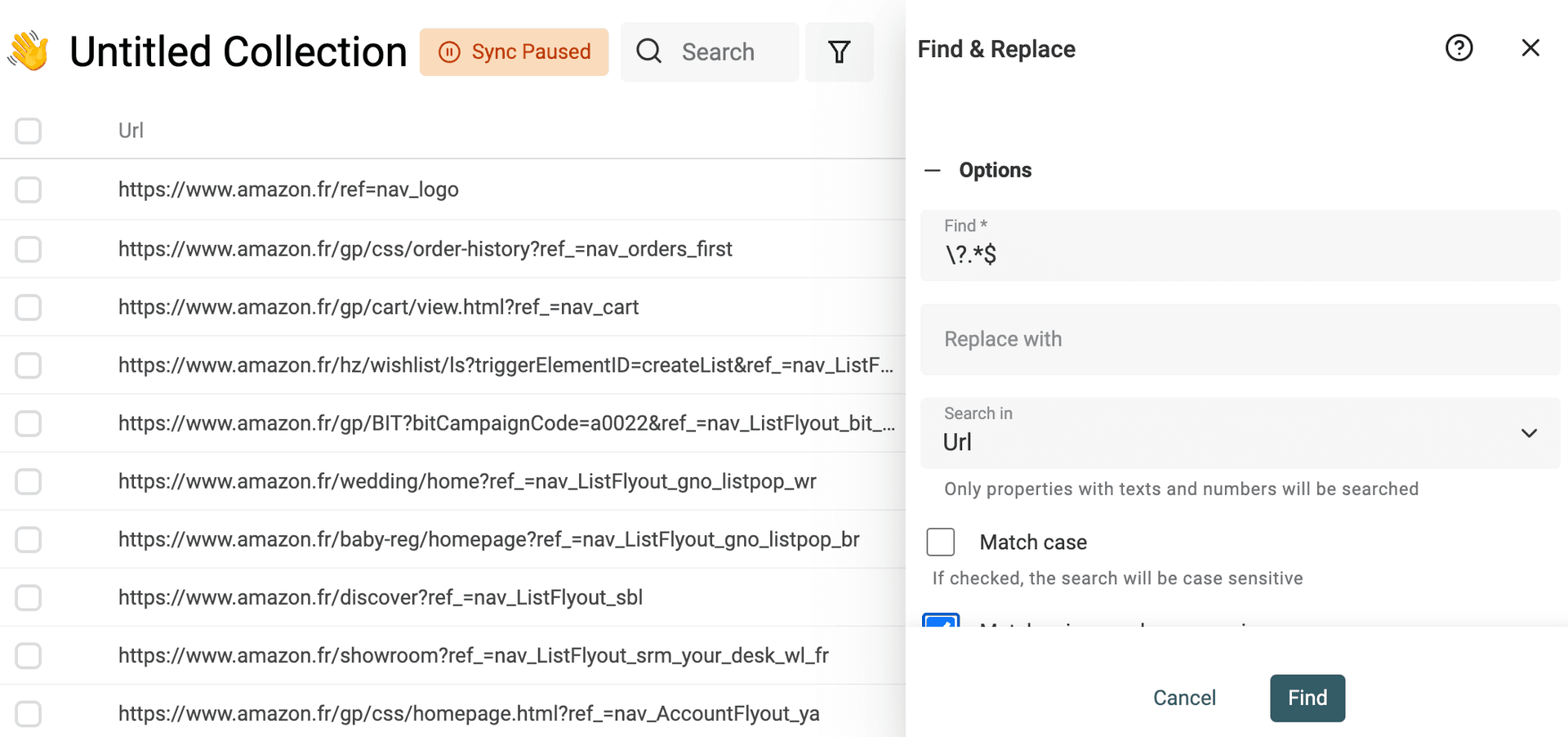
And apply it on your URL property.
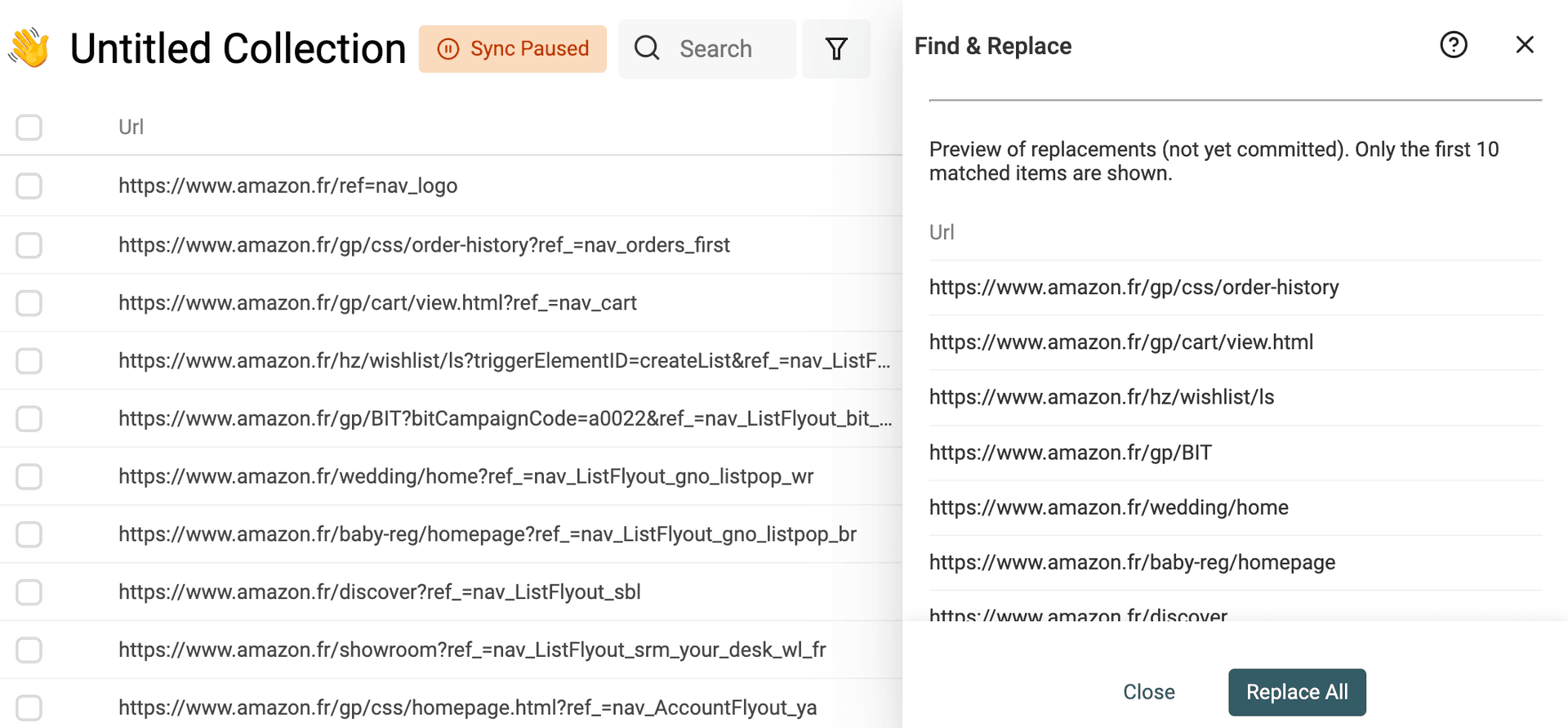
Get domain from email addresses
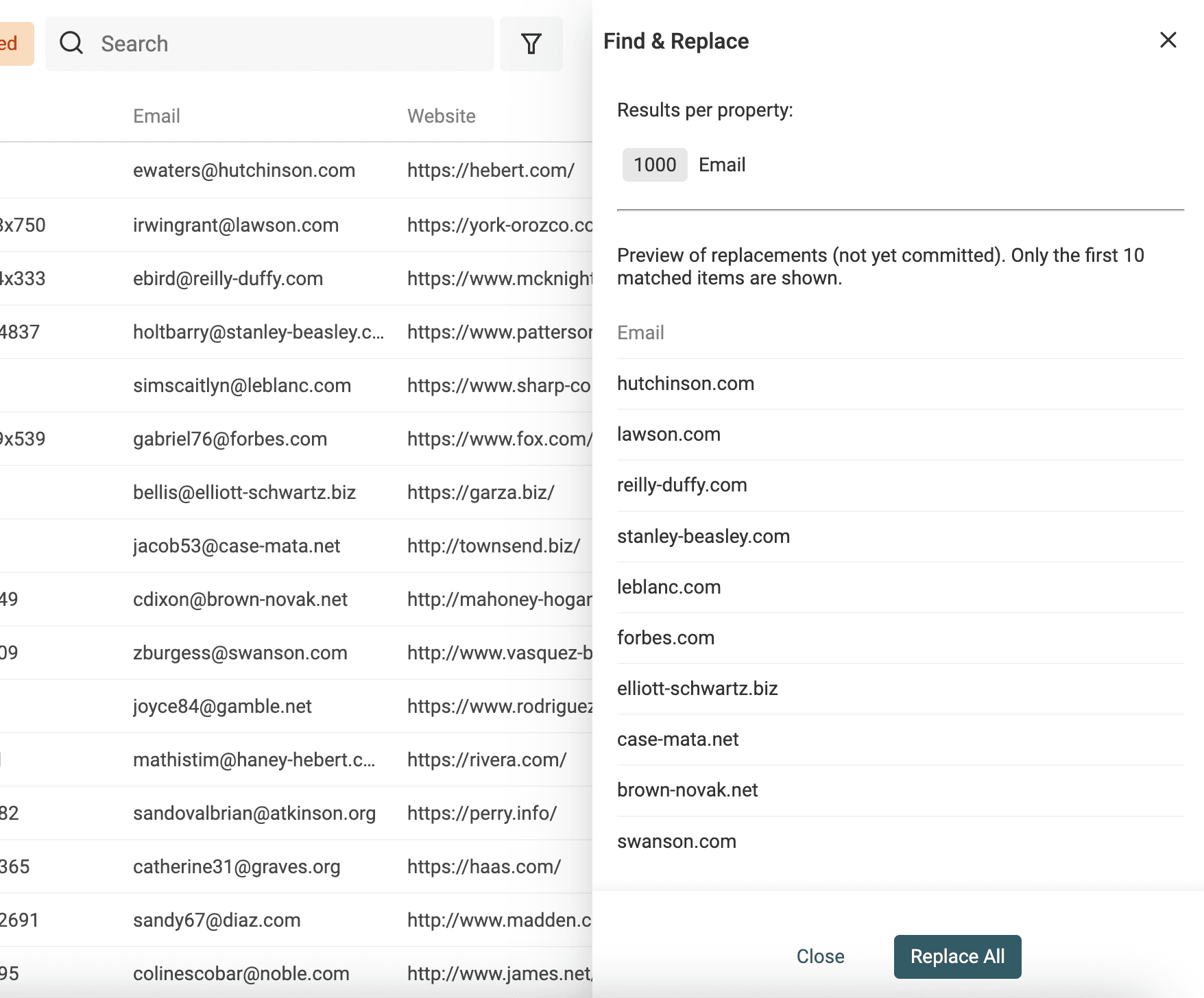
Another use of Find and Replace with regular expressions is to get website domains from email addresses.
Duplicate your email property to preserve your source data. And use the following regular expression with an empty replacement text:
^(\w)*@
Split Full Name into First Name and Last Name
When scraping lead lists, you get contact with "Full Name" that you have to split into "First Name" and "Last Name". Being able to accurately parse a person's name into its constituent parts is a crucial step.
Separating the first name and last name is useful to address individuals more personally in your cold emailing campaigns, to find your contact's gender, and to get the academic title.
The task of splitting names can be complicated. Fortunately, Datablist provides an easy-to-use tool to split "Name" into two values using the space as a delimiter.
To start, open the "Split Property" tool in the "Edit" menu.

Then, select your property with the names to parse. Select Space for the delimiter. And set the max number of parts to 2.

Run the preview. Datablist will parse your first 10 items to generate a preview. If the results are good, click "Split Property" to run the algorithm on all your current items.

After running the splitting algorithm, rename the two created properties with "First Name" and "Last Name".
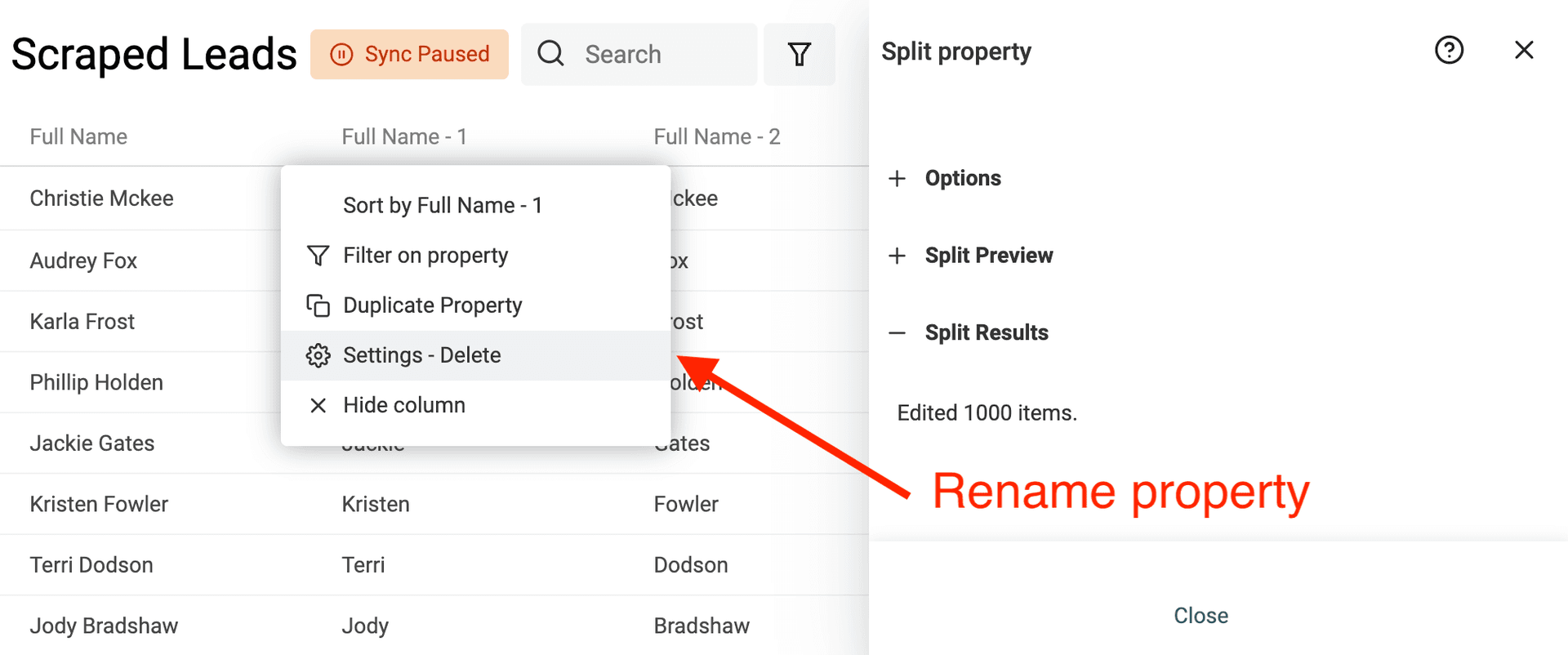
This example focuses on parsing names in the Western naming convention, which typically includes a first name and a last name. It can become more complex when dealing with non-Western names, including those with multiple given names or surnames. Or when names have titles or suffixes.
Data Deduplication
Datablist has a powerful deduplication algorithm to dedupe records. It finds similar items using one or several properties, and it has an automatic algorithm to merge them without losing data.
To run the deduplication algorithm, click "Duplicate Finder" in the "Clean" menu.
Select the properties to use for the matching process.
On the results page, run the "Auto Merge" algorithm once with only the option "Merge non-conflicting duplicates". It will merge duplicate items that are easily mergeable and list the properties with conflicts.
The dedupe algorithm has two options to deal with conflicting data. You can decide to "Combine conflicting properties" using a delimiter. Or to drop conflicting values to keep only one master item.

👉 Visit our guide on how to merge duplicates on CSV files. and out guide to find and merge duplicates using the company names.
Extract email addresses, URLs, etc. from texts
Datablist Data Extractor is a tool to parse unstructured texts and extract entities.
It uses pattern recognition to detect:
- Email addresses from a text
- URLs from a text
- Domain from URLs
- Domain from email addresses
- Mentions (e.g. @name) from a text
- Tags (e.g. #tag) from a text
The Data Extractor is perfect for data analysis and to structure your data. With well-formatted email addresses, URLs, etc. you can connect your data with other tools and create automated flows.
For example, once you get email addresses, you will be able to enrich them to find contact information. Or, using the domain from URLs, you can find the traffic ranking with Alexa for example.
Datablist Data Extractor is available from the "Edit Menu -> Extract url, email, tag, etc." menu.

Select the property with unstructured text and pick a parser.

Run the parser to get a preview. And if the preview results are ok, click "Extract" to process your items.

Use Regular Expressions to filter and validate data
Datablist let you use Regular Expression to filter your data.
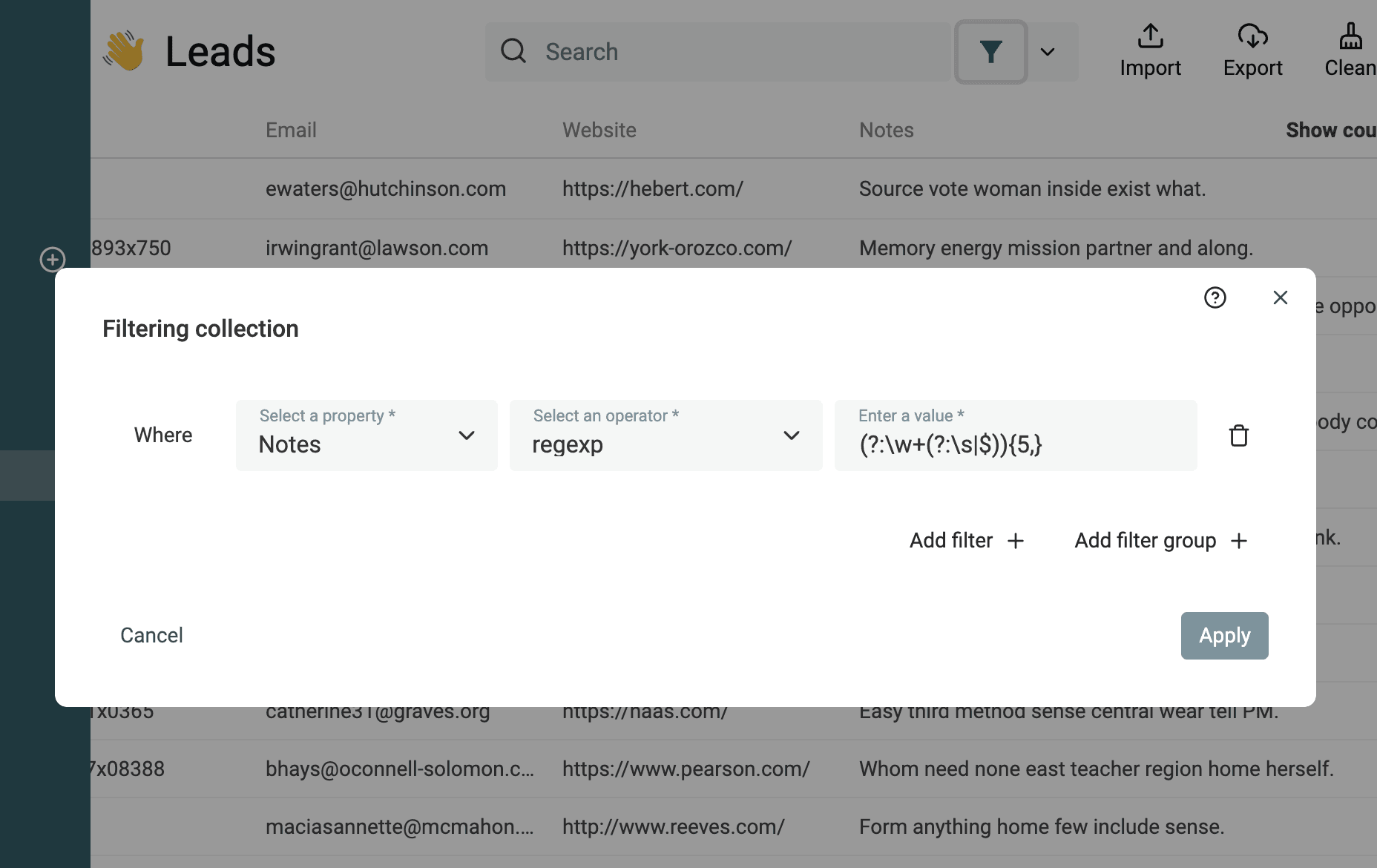
Text filtering based on the number of words
Using this Regular Expression, you can filter text with at least {n} words:
(?:\w+(?:\s|$)){5,} (replace the 5 with any number)
Other variations of this RegEx would be:
(?:\w+(?:\s|$)){,5}: Texts with less than 5 words (including texts with 5 words)(?:\w+(?:\s|$)){5,10}: Texts with between 5 and 10 words
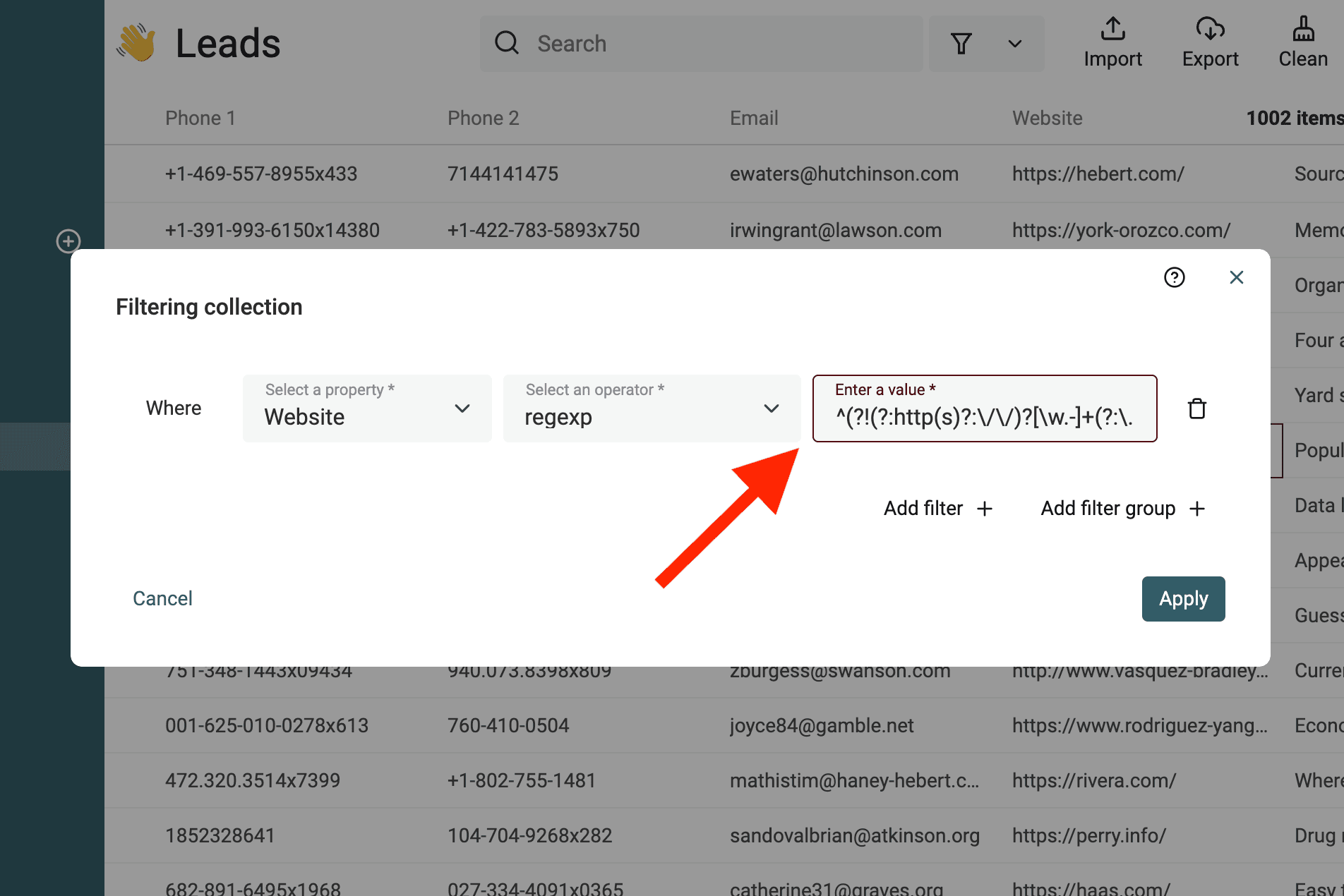
Filter invalid URLs
The following RegEx match invalid URLs:
^(?!(?:http(s)?:\/\/)?[\w.-]+(?:\.[\w\.-]+)+[\w\-\._~:/?#[\]@!\$&'\(\)\*\+,;=.]+).*$
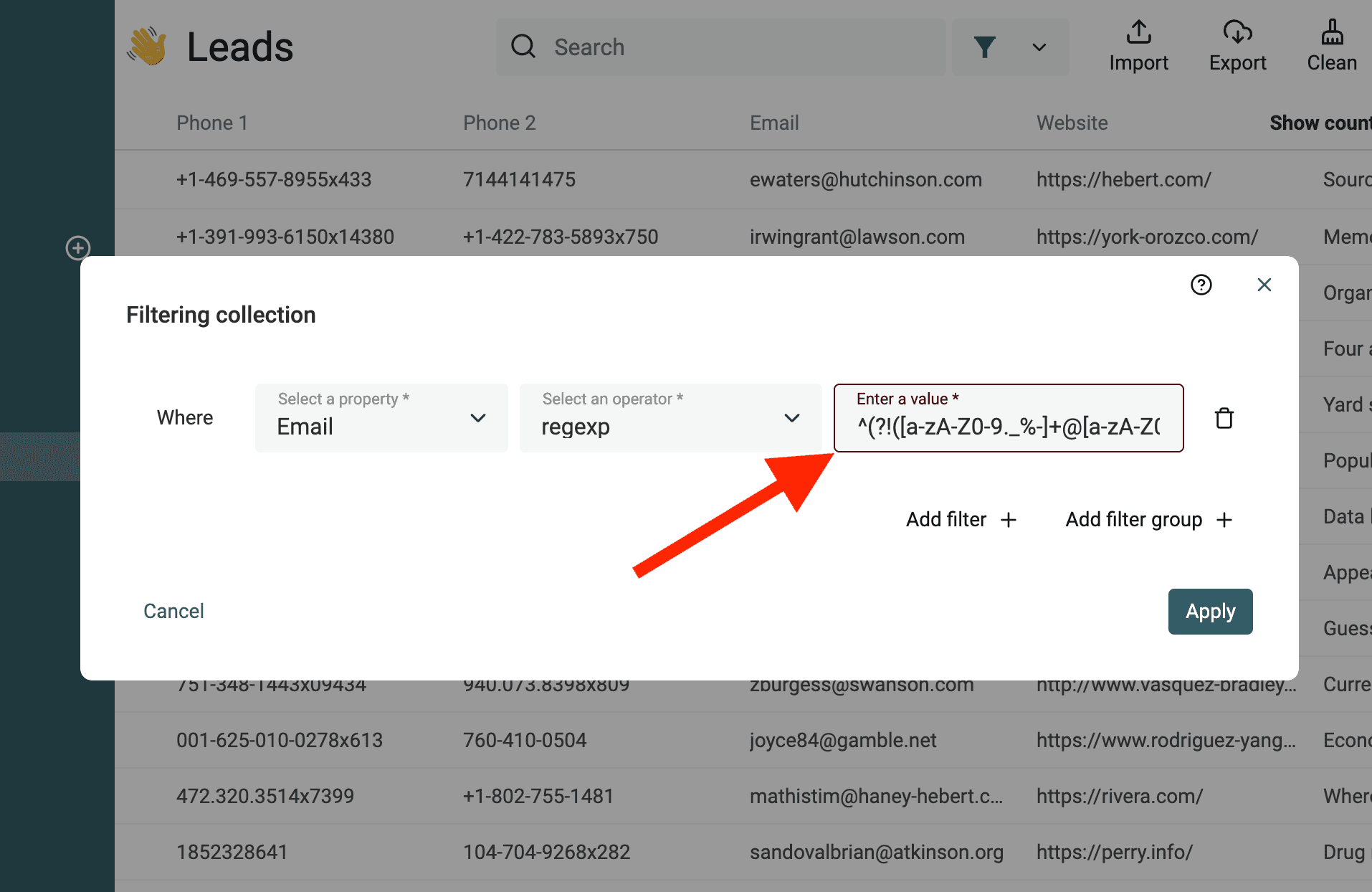
Filter invalid email addresses
The following RegEx match invalid email addresses:
^(?!([a-zA-Z0-9._%-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,})).*$
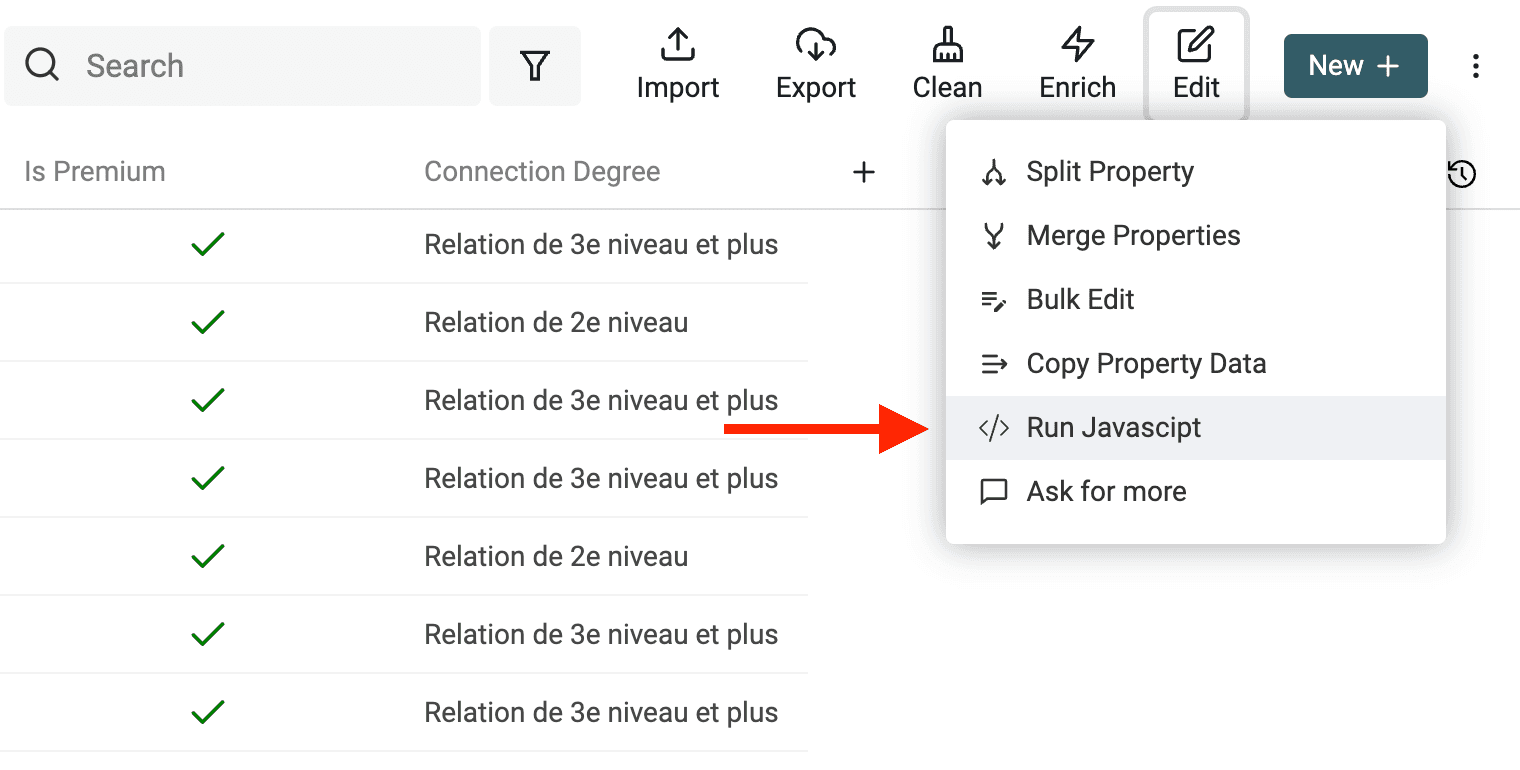
Write custom transformations with JavaScript code
Datablist lets you run custom JavaScript code on your data. With this ability to write custom code, you can address unique data challenges, handle specialized data formats, perform intricate calculations, and apply sophisticated data transformations.
This powerful feature allows you to unleash your creativity and expertise in data manipulation and transformation. You have the flexibility to apply custom logic, create loops, data conditions, and utilize a wide range of JavaScript functions to handle even the most intricate data-cleaning tasks.
Open the JavaScript editor by clicking on "Run JavaScript" from the "Edit" menu.
👉 Visit our documentation to learn more on how to write JavaScript code.
Validate Email Addresses
Data from scraping can be old, can have typos, or it can be invalid. This is especially true for email addresses that you get from scraping.
When the data is user generated, you will get fake email addresses in your database. Or email addresses from a disposable provider.
Datablist has a built-in email validation tool that let you validate thousands of email addresses.
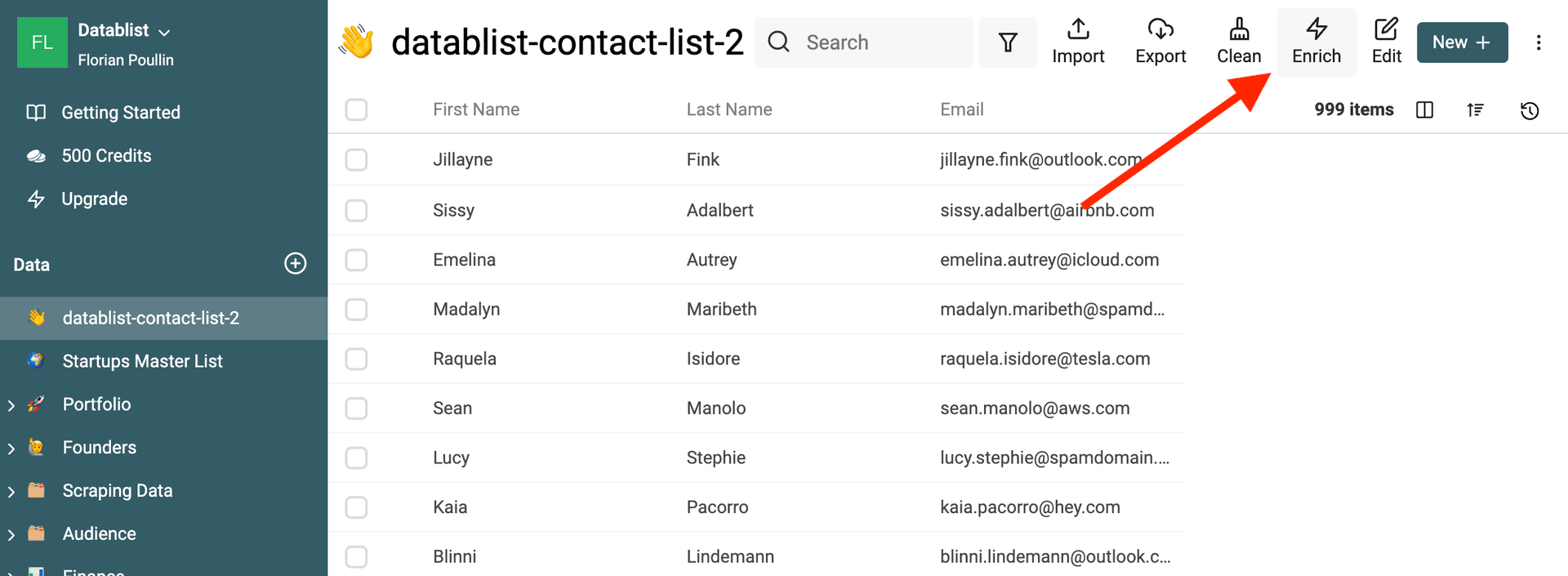
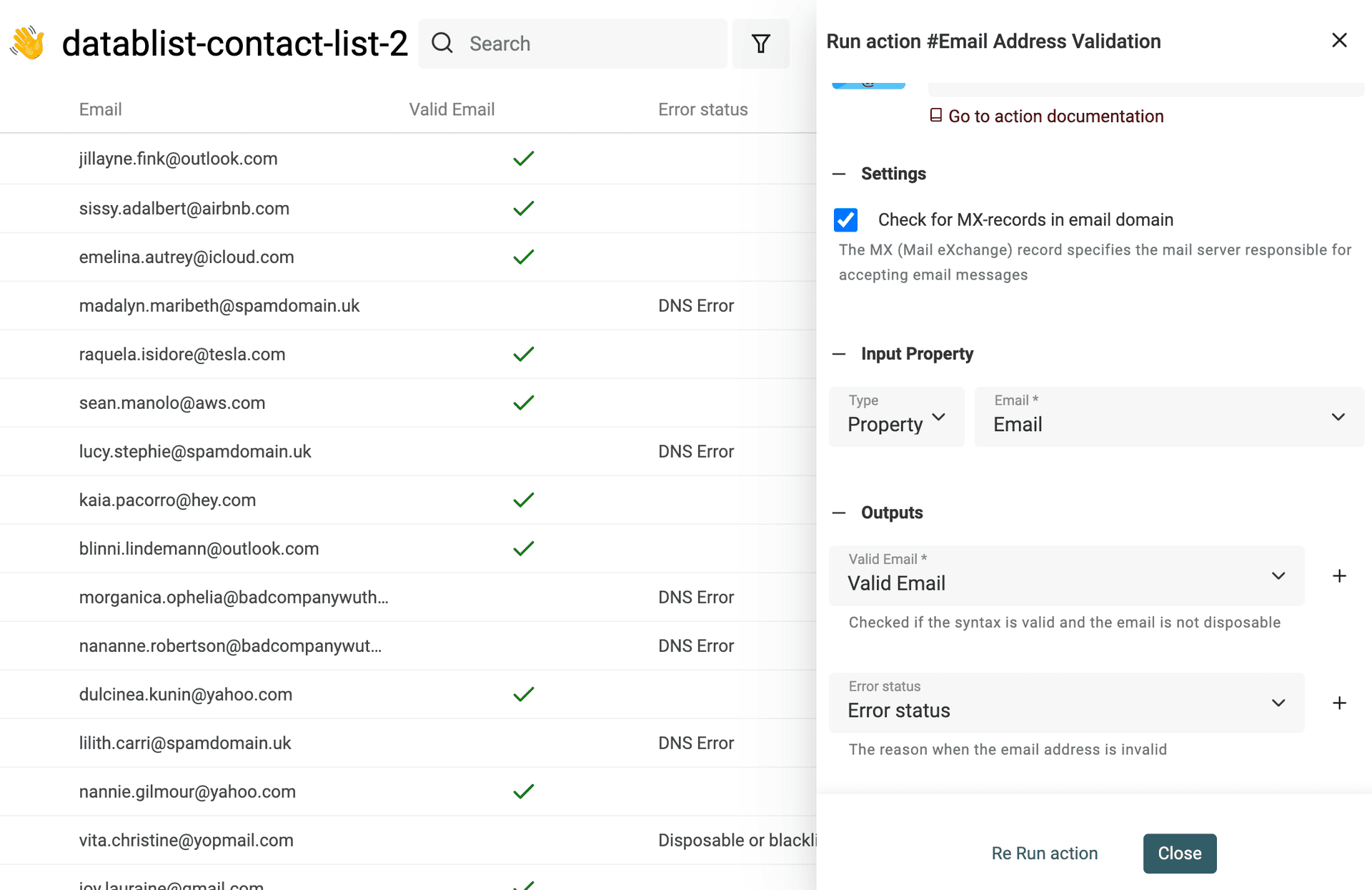
The email validation service provides:
- Email syntax analysis - The first check is to ensure the email conforms to the IEFT standard and does a complete syntactical analysis. This analysis will flag addresses without the at sign (@), with invalid domains, etc.
- Disposable providers check - The second check is to detect temporary emails. The service looks for domains belonging to Disposable Email Address (DEA) providers such as Mailinator, Temp-Mail, YopMail, etc.
- Domain MX records check - A valid email address must have a corresponding domain name with configured MX records. Those MX records specify the mail server accepting the email messages for the domain. Missing MX records indicate an invalid email address. For every email address domain, the service checks the DNS records and looks for the MX ones. If the domain doesn't exist, the email will be flagged as invalid. If the domain exists and doesn't have a valid MX record, it will also be flagged as invalid.
- Business and Personal Email addresses Segmentation - With prospects from lead magnets or to segment your user base, you might want to segment your contacts between business emails and personal ones. The email validation service gives you this information to enrich your contacts' data.
FAQ
What is data cleaning and why it's important?
Data cleaning, also known as data cleansing or data scrubbing, refers to the process of identifying and correcting or removing errors, inconsistencies, and inaccuracies in a dataset. It involves detecting and rectifying problems such as missing values, duplicate records, formatting errors, outliers, and inconsistencies in data representation.
Data cleaning is a crucial step in data processing, as it ensures that the data is accurate, reliable, and suitable for analysis or use in various applications.
What are the other free tools for Data Cleaning?
The data-cleaning landscape goes from generic tools such as spreadsheet tools to specialized applications. Here is a list of recommended free tools other than Datablist you can use for your data-cleaning operations.
OpenRefine
OpenRefine (formerly known as Google Refine) is an open-source tool focusing on exploring, cleaning, and transforming messy and inconsistent data.
OpenRefine is a standalone desktop application compatible with tabular files (CSV, TSV), Microsoft Excel files, and other structured files such as JSON and XML files.
OpenRefine is very useful to deal with invalid CSV files:
- It manages CSV encoding issues very well
- It offers options to solve CSV format errors
On the weak points, OpenRefine has a steep learning curve and lacks some business-related features. It doesn't have deduplication capability or simple workflows to join a dataset with another list to update or consolidate data. It also lacks collaboration features and business-related enrichments and integrations.
Microsoft Excel and Google Sheets
Microsoft Excel and Google Sheets are powerful spreadsheet applications that can be utilized for data cleaning and preparation tasks. Although they have some differences, both tools offer a range of features and functionalities that make them useful for cleaning and transforming data.
You can use formulas to do data transformation and manipulation. And with conditional formatting, you can highlight invalid values that require manual handling.
Need help with your data cleaning?
I'm always looking for feedback and data cleaning issues to fix. Please contact me to share your use case.