
Step-by-step guide
Step 1: Load your CSV or Excel file on Datablist
Create a free account and import your data file. Datablist is a powerful CSV editor. Perfect for opening large CSV files or Excel files with a list of items.
Create a new collection and import your file.
Step 2: Select the "Smart Scraper" enrichment
Click on the "Enrich" button, and search for "Smart Scraper".

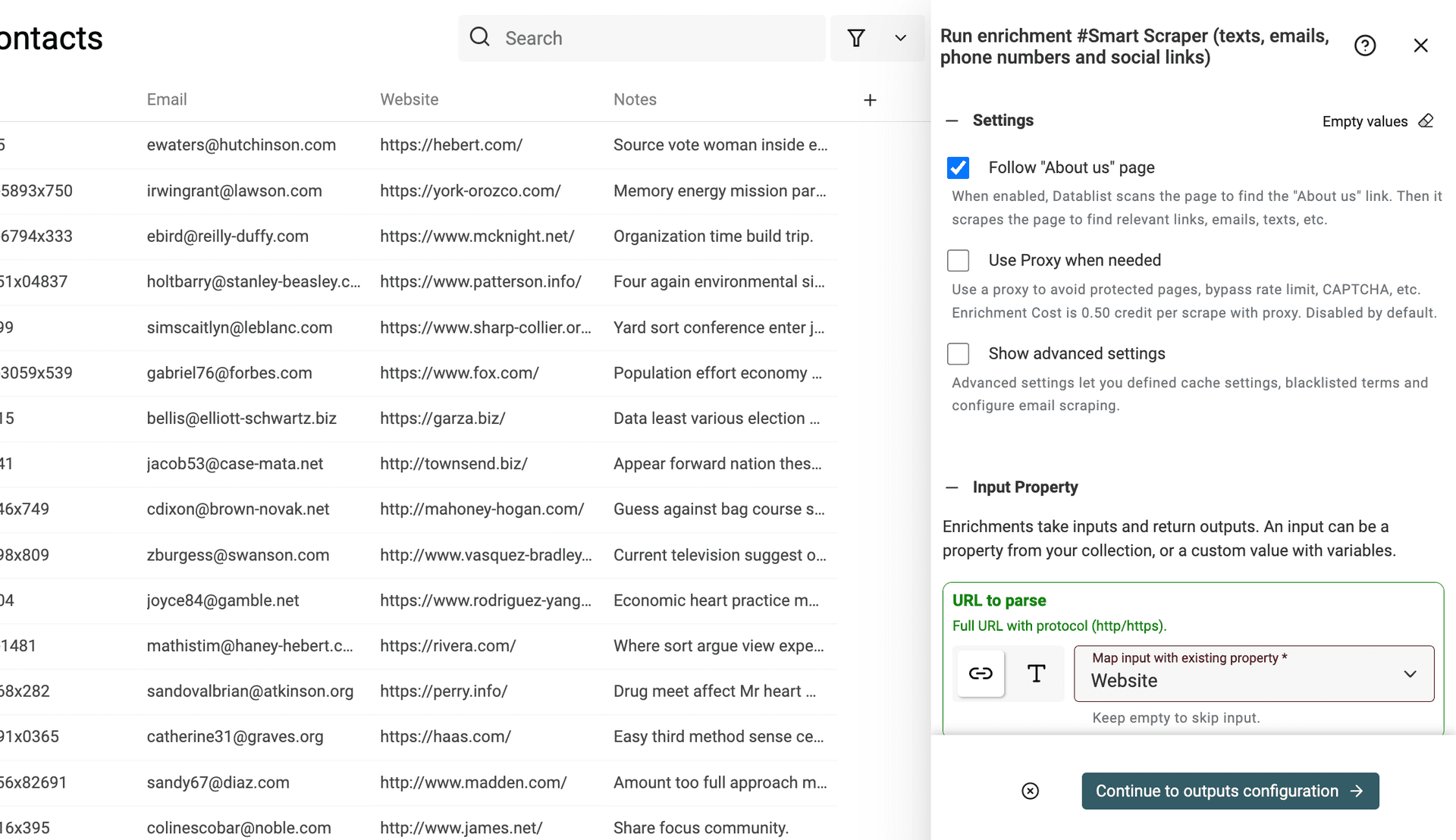
Step 3: Configure options and enable proxy if needed
The next step is to configure the scraper.
A nice feature is the option to automatically follow "About us" links. When enabled, the Smart Scraper scans the webpage to find links pointing to an "About us" page. It uses a list of common "About Us" paths, as well as link anchors analysis to match "About us" page patterns.
Another option is to define the use of a proxy. Some websites are protected from scraping or have rate limits. You can use a proxy automatically when the Smart Scraper receives an error. The proxy option is useful for e-commerce websites or if you are scraping several pages of the same website.
Note: The cost per URL to scrape is 0.50 credits with the proxy, and 0.10 credits without. When the proxy is used as a fallback, you won't be charged for the proxy if the URL returns a valid response with a simple scraping.
In the advanced settings, you can define blacklist terms to exclude emails or links to be scraped.
Step4: Select the column with the Webpages as inputs
Now, you need to select the column from your collection with the website or webpage to scrape.
Move to the "Input Property" section and select the property using the dropdown menu.
Step 5: Define where to store extracted texts, links, and email addresses
The enrichment returns extracted texts, email addresses, phone numbers, and social links. Create a property or map to an existing property to store the results.
When multiple phone numbers/links/emails are found, they are returned with a comma between each.

How to use the extracted texts with ChatGPT?
The Smart Scraper not only returns phone numbers, emails, social links, etc. It also returns an aggregation of relevant texts found on the scraped page, including on the "About us" page.
It automatically discards header texts, footer texts, etc., and tries to keep only texts that bring context information.
This text is perfect to be used as input in a ChatGPT prompt.
For example, you can use the extracted texts to segment websites that target B2B and B2C customers.

Giving you the following results:

Use Cases
Lead Generation
Gathering email addresses and LinkedIn profile links from webpages is perfect to enrich company data. Sales teams can use this information to reach out to relevant individuals or businesses with targeted sales pitches or marketing campaigns.
Recruitment and Talent Sourcing
HR professionals and recruiters can use scraped email addresses and LinkedIn profile links to identify potential candidates for job openings. This enables them to proactively reach out to qualified candidates and build a talent pipeline.