
Want to extract URLs from a website Sitemap?
Whether you're collecting data, analyzing site structures, or finding hidden pages, Datablist's Sitemap Scraper makes it easy.
This guide walks you through the process, step by step.
Extract URLs from any Sitemap in Seconds
Websites often have thousands of pages. Manually listing them is impossible. But most websites provide a sitemap, a file listing all URLs.
The Sitemap Scraper reads this file and extracts URLs in bulk.
- No coding needed – Just enter the sitemap URL.
- Finds Everything - Automatically follows sitemap indexes to scrape all URLs, even on massive, complex sites.
- Handles Protected Sitemaps - Uses a built-in proxy system to browse reliably and avoid blocks.
- Filter results - Get only the pages you need by filtering URLs with regular expressions.
Let’s see how you can scrape URLs using Datablist.
Step-by-Step Guide: How to Use the Sitemap Scraper
Datablist is a powerful data extraction and list-building tool. Follow these steps to extract URLs from a website.
1. Create a New Collection
First, create a new collection in Datablist. Then, open the Sources list.

2. Select "Sitemap Scraper"
Choose Sitemap Scraper from the available data sources.

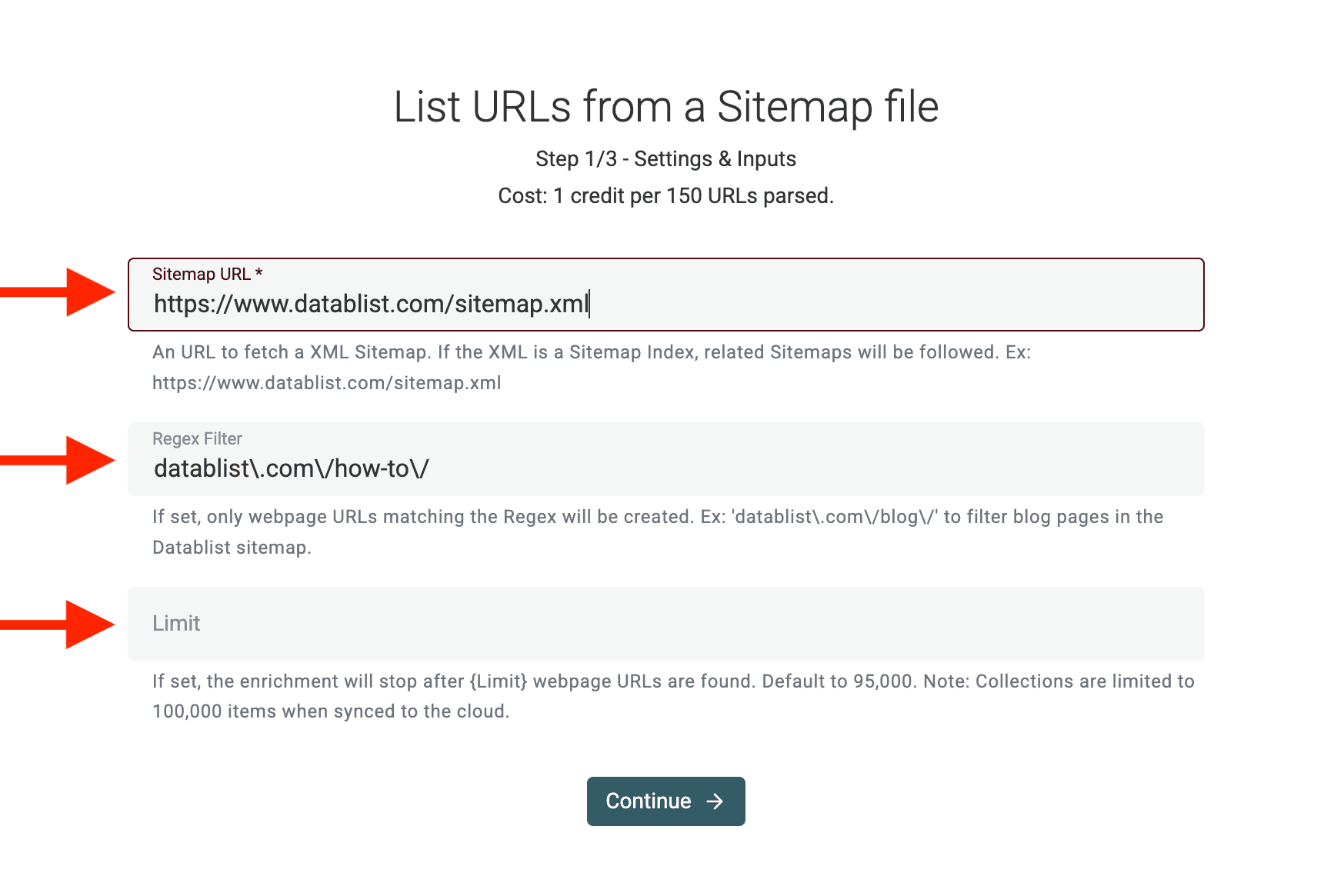
3. Enter the Sitemap URL & Regex Filter
Most websites store their sitemap at:
https://example.com/sitemap.xml
For example, for Datablist, it is https://www.datablist.com/sitemap.xml

If you don’t know the sitemap URL, try:
- Adding
/sitemap.xmlto the domain. - Checking robots.txt: Visit
https://example.com/robots.txt, where sitemaps are often listed.
Paste the sitemap URL into Datablist.
Need only blog posts? Product pages? Exclude certain URLs?
Apply filters to include or exclude URLs based on patterns (e.g., only pages containing /blog/).
Note: The filter setting accepts a Regular Expressions.
4. View the Extracted URLs
Once done, you’ll see all the URLs in your collection.
For each extracted page, you get the following values:
- Page URL
- Page Last Updated

You can export them to CSV, analyze them, or enrich them with more data.
Why Use the Sitemap Scraper?
The Sitemap Scraper is useful for:
- SEO Audits – Get a full list of pages for analysis.
- Competitor Research – See what pages your competitors have.
- Lead Generation – Extract all product or service pages.
- Web Scraping – Collect URLs before running a content scraper.
- Finding Hidden Pages – Discover URLs not linked in navigation.
Advanced Use Cases
SEO Audits & Broken Link Checks
Want to audit your website?
- Extract all URLs.
- Check for missing pages (404s) or duplicate content.
- Ensure all key pages are indexed.
Example: An SEO consultant can scrape a client's sitemap to review their content structure.
Competitor Research
Want to analyze a competitor’s website?
- Extract their URLs.
- Identify their content strategy.
- Find pages they rank for.
Example: A marketing agency can scrape a competitor's sitemap to find their most valuable content.
Lead Generation
Want to generate leads?
- Extract product or service pages from industry websites.
- Find potential business contacts.
- Build a prospect list.
Example: A B2B sales team can extract service pages from a directory site.
Pricing: Affordable & Scalable
The Sitemap Scraper is cost-effective.
- 1 credit per 150 URLs parsed.
- $20 = 20,000 credits (enough for 3 million+ URLs).
Try the Sitemap Scraper Now 🚀
Extract URLs from any website with Datablist.