

Managing duplicate records across multiple Excel files is a time-consuming nightmare that leads to data inconsistencies and costly errors.
Without a reliable deduplication process, you risk sending multiple emails to the same contact, making incorrect business decisions based on duplicated data, and wasting hours manually comparing records.
Learn how to efficiently deduplicate data across multiple Excel files using proven techniques and tools that will save you time, maintain data integrity, and prevent future duplications.
In this guide, you will learn how to remove duplicate records across multiple lists that have different structure:
- How to import your different Excel files
- How to match duplicate records across multiple lists
- How to automatically remove duplicates
Step 1: Import the files to dedupe on Datablist
Sign up for Datablist and import at least two files.

Make sure you have at least one unique identifier in your files.
Note: Datablist Duplicates Finder can work with any number of Excel/CSV files. They can have different structure. They just need a matching identifier on each listing file.
I chose the LinkedIn URL of my prospects as unique identifier.
A unique identifier doesn't have to be completely unique — it can also be a company name or a first name, as long as you categorize it as your unique identifier.
Step 2: Find Duplicate Records Across your lists
Then, click on “Clean” and select the “Duplicates finder”.
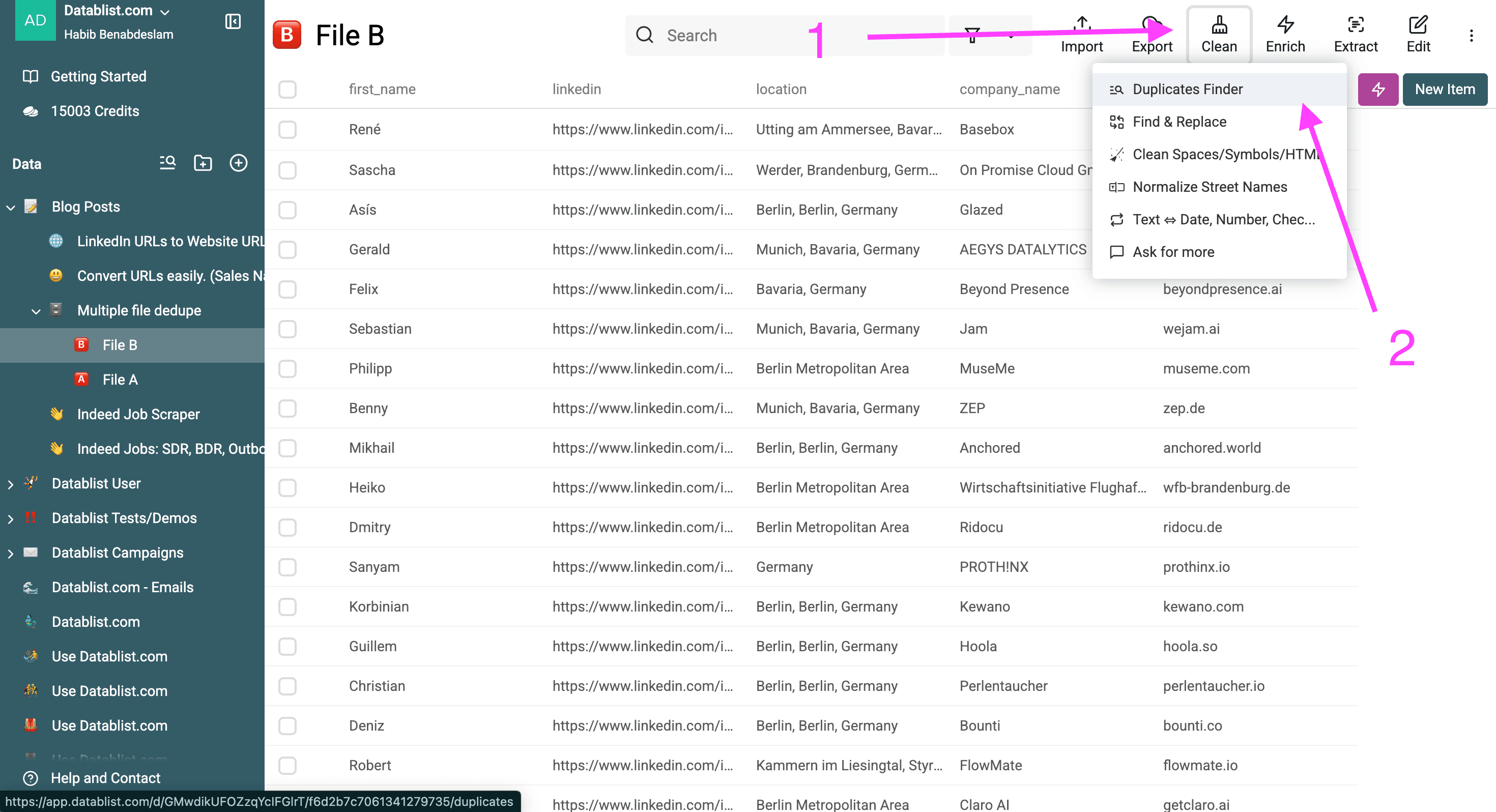
Note: You can start from your file of choice. The process and results will be the same.
Set everything up to deduplicate across your CSV files.
- Click on "Selected Properties and Multi Collections" and
- Click on "Check Duplicate Items Across Several Collections"
- Select the collections you want to deduplicate across — you can select two files or more with no limit.
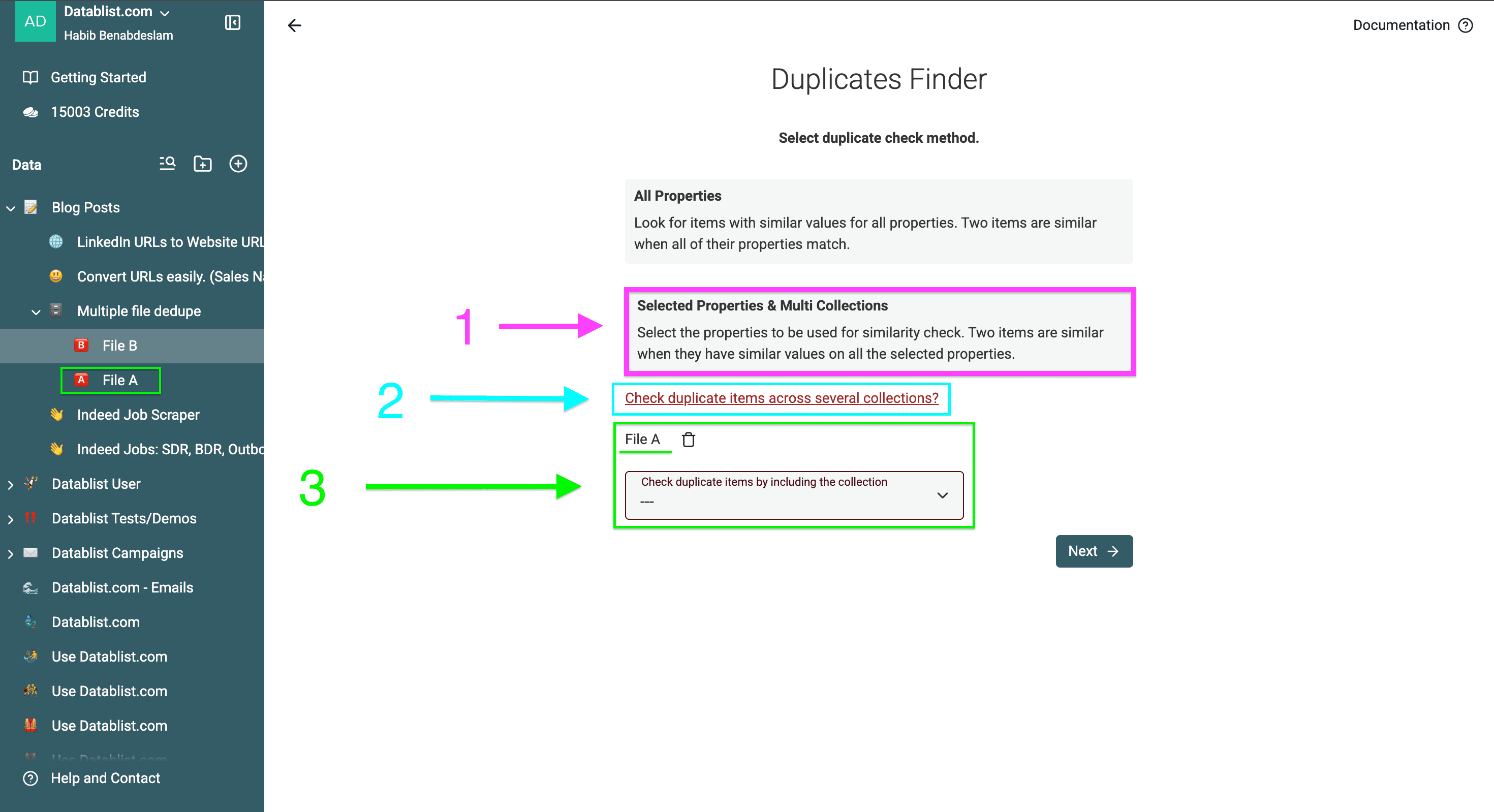
Choose the property you want to use for your deduplication.
A similar property must exists on each of your files. For each property to use for the deduping, you have to select a matching property on each collection.
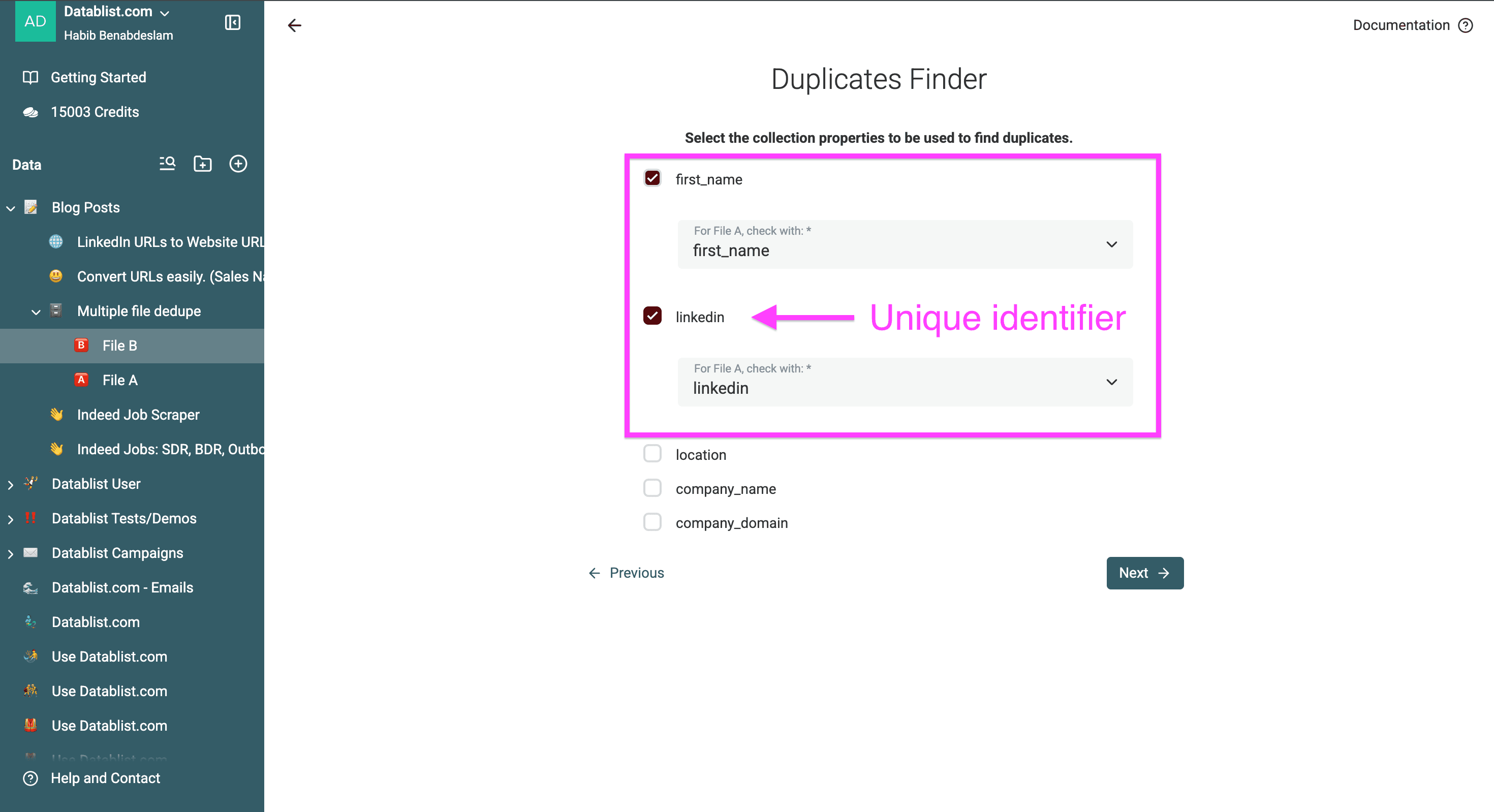
For my example, I'll remove all the prospects in "File A" from "File B" based on the LinkedIn URL.
You can select multiple properties for the duplicate matching. In this case, records would need to have matching values for all properties. If you want to find duplicates on a property OR another, perform the process twice. One for each property.
Select the comparison mechanisms you want to work with.
For IDs (CRM Ids, Internal Ids), I always use "Exact". For text-based properties such as URLs, Emails, etc. I go with the "Smart" algorithm for maximum accuracy when deduplicating multiple files.
If you have Names that might have typos or slight variations, use one of the distance algorithms (Levenshtein Distance or Jaro-Winkler Distance).

Click on “Run duplicates check” once you’ve chosen the one that suits your deduplication needs best.
Step3: Choose the cleaning operations for duplicates
Set up cleaning rule by choosing between:
- Removing duplicate items from collection X
- Keeping duplicate items only in collection X (this option is only available when deduplicating across 3 or more collections)
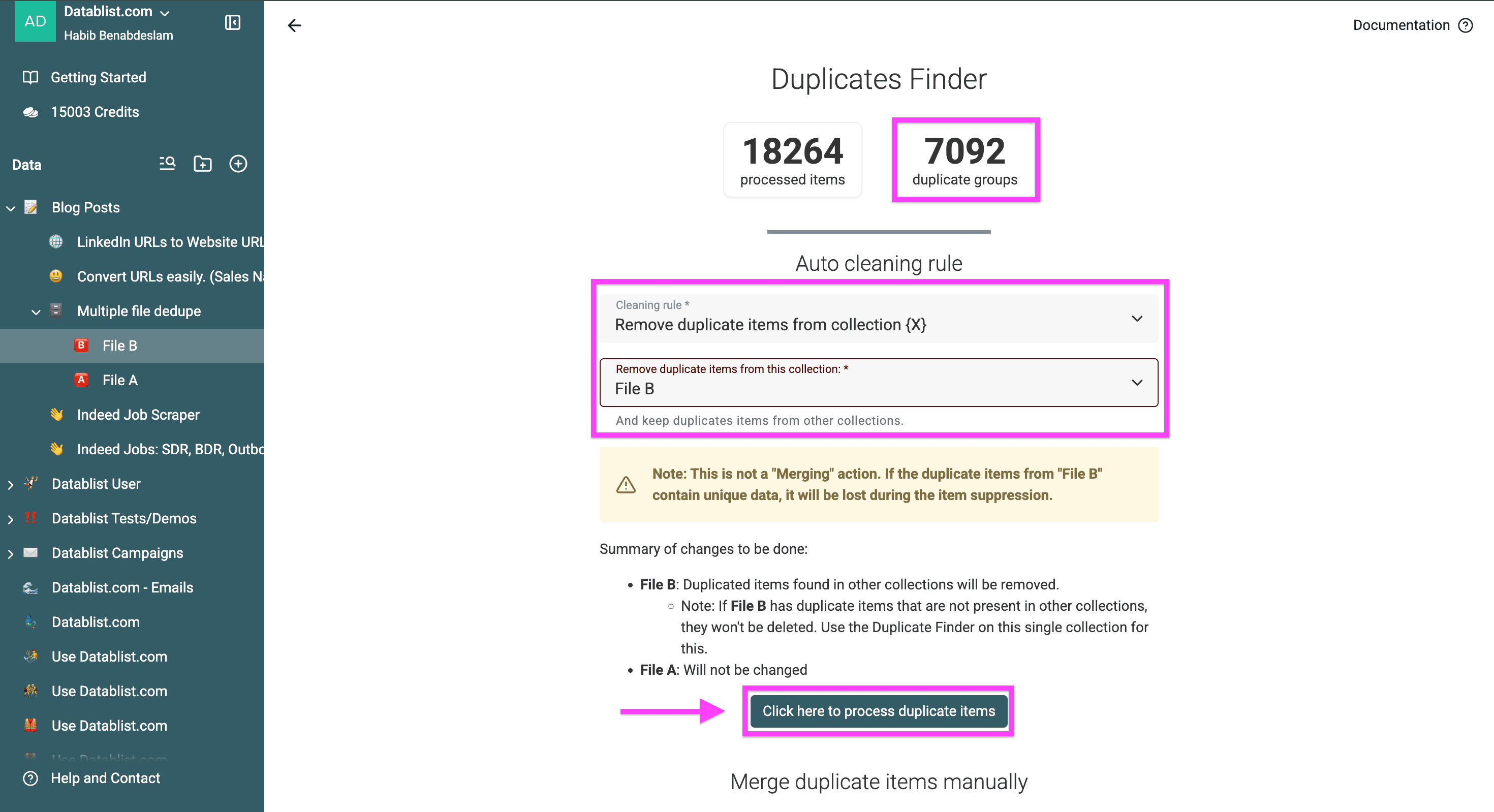
Click on "Process duplicate items" to continue.
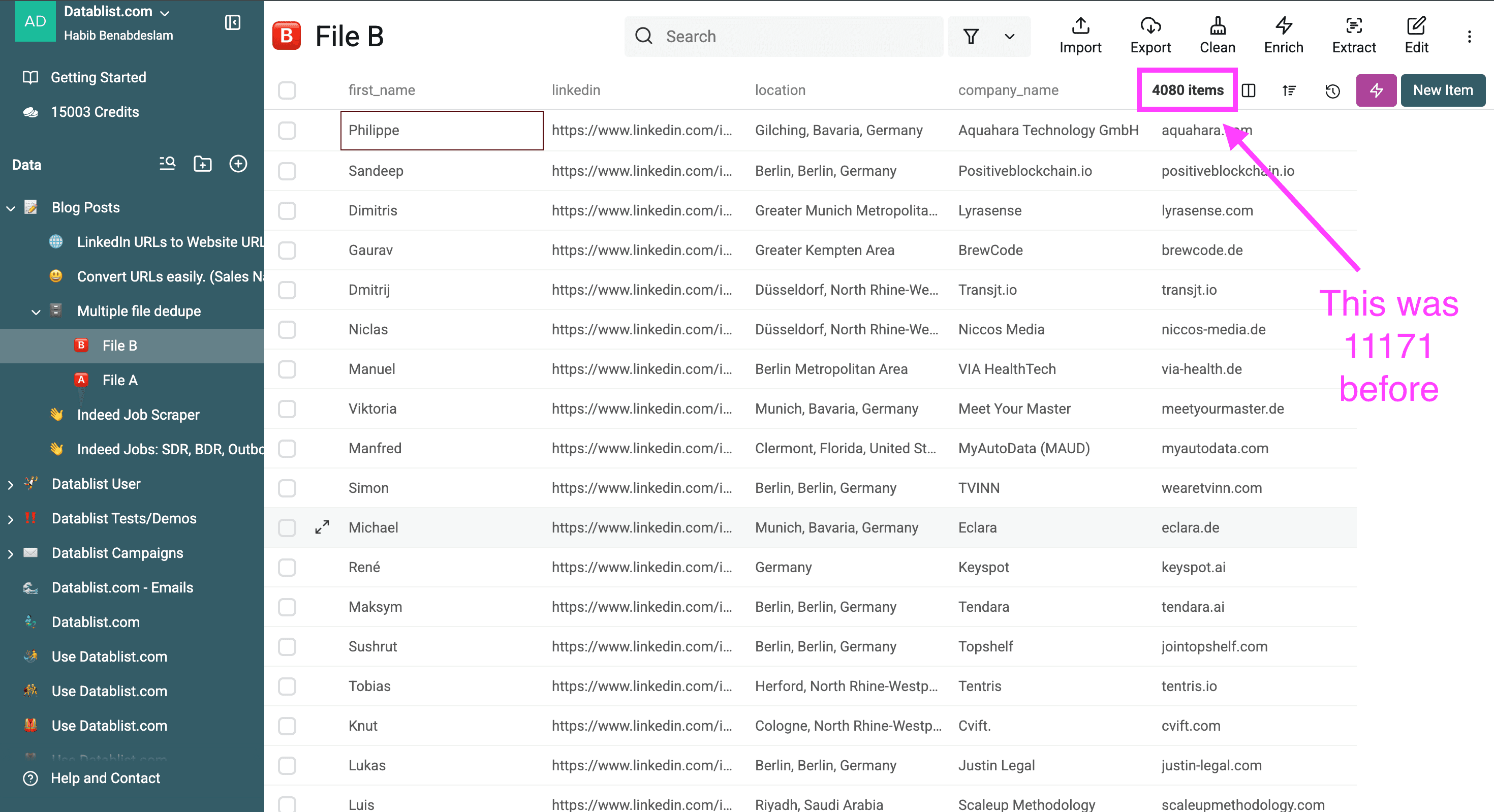
My cleaned file now contains only new prospects with no duplicates.
Important - When deduping across several lists, the algorithm doesn't remove duplicates inside a single file. If duplicate records exist within a file, start by running the deduplication process on each file first.
Use cases for this workflow
- Avoiding contacting the same prospect twice.
- Prevent contacting multiple people from the same company.
- Consolidate customer data from various departments or branches.
- Clean and merge multiple contact lists from different sales campaigns.
- Consolidate customer feedback or survey responses from multiple sources.