

Got a messy list full of duplicates? It might be in customer contacts, email subscribers, or product inventory, duplicate entries must be removed or they will waste your time and money. Imagine sending the same email twice to a customer—it’s not just annoying, it can hurt your brand’s reputation.
The good news? You can dedupe your list online for free with Datablist. It’s a simple and powerful online tool that helps you remove duplicates and clean up your data quickly. No coding, no headaches.
In this guide, we’ll show you how to dedupe a list in three easy steps:
Part 1: Import your list with duplicates
The first step to dedupe your list online with Datablist is super simple: getting your data into the platform.
Datablist plays well with different listing formats (CSV, Excel), and you can also load your data from external sources such as Pipedrive.
Step 1: Create a New Collection
Think of a collection in Datablist like a spreadsheet. To get started, you'll need to create a new collection for the list you want to dedupe.
Click on the "+" button on the sidebar to create a new collection.

On your new collection, click on the "Import CSV/Excel" link. Or click "Sources" for more advanced integration.
Once it's uploaded, Datablist will show you a preview of your data, with columns (called properties) and a few rows. Take a quick look to make sure everything looks right.
Part 2: Finding Duplicates in the list
Your list is ready. Now, let’s hunt down those duplicates.
Datablist uses advanced algorithms to spot records that are likely duplicates, even if they're not exactly the same.
Step 1: Open the Duplicates Finder
To start the hunt for duplicates, go to the "Clean" menu in your Datablist collection and click on "Duplicates Finder."
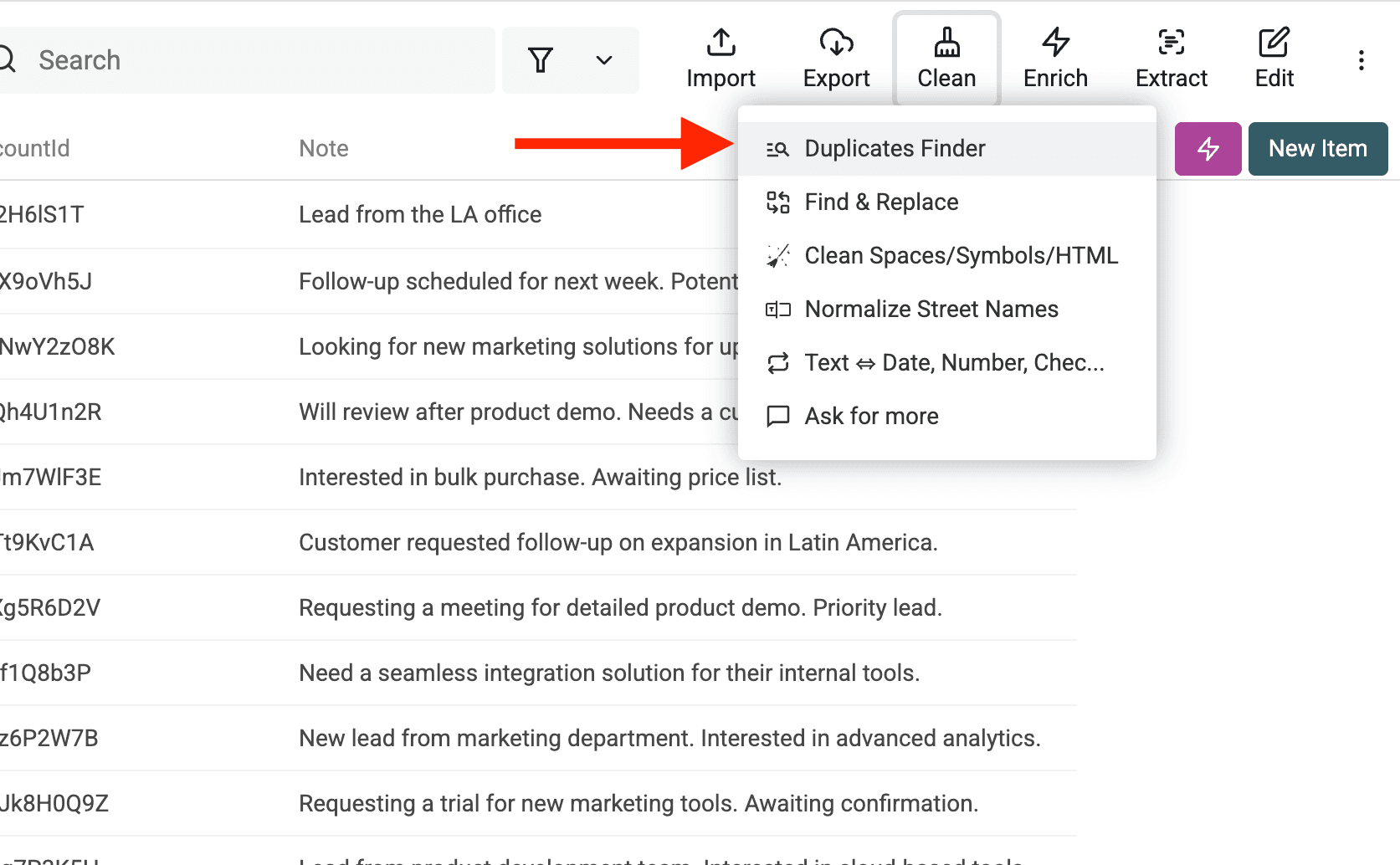
This will open up the Duplicates Finder, where you can tell Datablist how to look for duplicates in your list.
Step 2: Pick What to Compare: Deduplication Properties
A "deduplication property" is just a fancy way of saying the specific column (or field) in your list that Datablist will use to compare records and see if they're duplicates.
Pick the right one based on your list type:
For example:
- Contact Lists: For a list of people, the email address is often the most reliable thing to compare, as most people have unique email addresses. If you don't have email addresses for everyone, you could also use their name or both first name and last name.
- Product Lists: If you have a list of products, you might use the product name or a unique product ID (EAN, GTIN, SKU).
- Company Lists: For a list of companies, the company name or their website URL could be good options.
In the Duplicates Finder, you'll be asked to select one or more properties to use for matching.

Step 3: Select Matching Algorithm & Processor
Datablist gives you a few different ways to compare your data, depending on how strict you want to be:
- Exact: This only finds records where the property you picked is exactly the same. It's great for finding truly identical entries.
- Smart: The Smart algorithm is a bit more forgiving. It can spot things like URLs that are the same but start with different things (like http vs. https) or text that has minor differences in punctuation.
- Phonetic (Double Metaphone): This one's cool! It matches records based on how they sound, not just how they're spelled. This is super handy for names where there might be different spellings but they sound the same.
- Fuzzy Matching (Jaro-Winkler & Levenshtein): Fuzzy matching is really smart. It calculates how similar two pieces of text are. You can set a level of similarity, so it will flag records as duplicates even if they have typos, abbreviations, or slight wording differences.
Note: The Exact algorithm is available for anonymouse users. The Smart algorithm requires a free account. And the Metaphone and Fuzzy Matching algorithms are only available for the paid plans.
Pick the algorithm that makes the most sense for each of your deduplication properties.
You also need to define the best processor to normalize your data before the deduplication. This ensures similar values match, even if they have slight differences.
Common processors in Datablist:
- URLs - Removes protocols (http, https), query parameters, and tracking codes to match equivalent links.
- Example: https://example.com?utm_source=newsletter → example.com
- Emails - Ignores aliases like +filter in Gmail addresses, so variations match.
- Example: john+work@gmail.com → john@gmail.com
- Company Names - Strips legal suffixes (Inc., LLC), business terms (Partners, Group), and geographical terms (Europe, USA).
- Example: Acme Inc. → Acme
Note: The Company Names processor is only available for the paid plans.

Dedupe fields with several values - If your deduplication property contains multiple values, check the "Multiple Values" settings.
👉 Important: Dedupe in several processes
For most lists, starting with "Smart" matching and then doing another pass with "Fuzzy matching" on the same property or a different one (like name if you first matched on email) is recommended.
The duplicates found with the "Smart" algorithm are most of the time true duplicates. So you can merge them without much extensive validation.
But for distance algorithms, you can have "false positives". Two names with a different letter can or can not be the same entity. So, you need to be extra careful when reviewing those duplicate groups (see later).
✅ Pro Tip: Start with Smart Matching, then refine with Distance (Fuzzy) Matching.
Step 4: Run the Deduplication Check
Once you've chosen your matching properties and algorithm(s), just click the "Run duplicates check" button to start the deduplication process.
Datablist scans through your list and groups together records that it thinks are potential duplicates based on what you told it.
Step 5: Review the Detected Duplicate Groups
After the scan is done, Datablist will show you a list of "Duplicate Groups".
Each group contains two or more records that it thinks are duplicates.
In each duplicate group, you can see how they match, and if they have conflicting values.

This is an important step because it lets you double-check that the matching is accurate and that you're not accidentally grouping legitimate records together.
Note: If you only need to have the list of duplicates, you can download a CSV/Excel file with the duplicate groups. Each duplicate group has an unique identifier. You also have the number of duplicates in your file if you only need statistics.
Part 3: Resolving and Merging Duplicates
Okay, you've found the duplicates! Now it's time to dedupe your list by merging them.
This involves figuring out what to do with any conflicting information and then merging the duplicate records into a single, clean entry.
Step 1: Understanding Duplicate Groups and Conflicts
When you look at a group of duplicates, you might notice that some of the information in the different records is slightly different. These are called "conflicting values".
For example, two duplicate contact records might have the same email address but different phone numbers or job titles.
Step 2: Setting merging rules for Conflicting Values
Datablist lets you decide how to handle these conflicting values when you merge duplicates. You can set up rules to tell Datablist which value to keep or how to combine them.
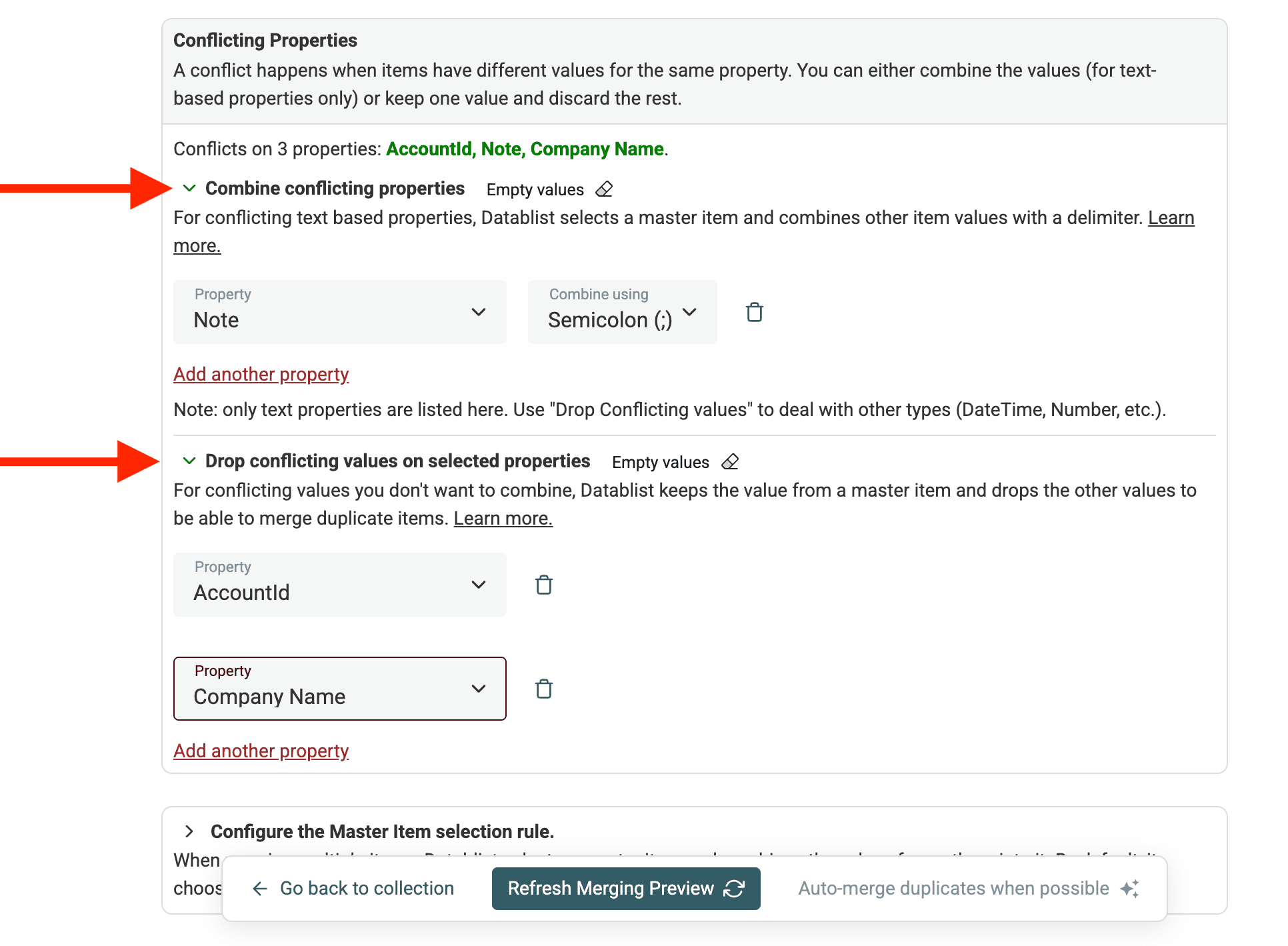
The two options to deal with conflicts are:
- Combine Conflicting Values: If the values are complementary (e.g., multiple phone numbers, notes), combine them.
- Drop Conflicting Values: If you only need the value from one record and you want to discard the other, select "Drop conflicting values...".
For the Combine conflicting values and Drop conflicting values settings, you have a shortcut link to automatically select all conflicting properties.
Example of Combining Multiple Values:
Let's say you have two duplicate contact entries:
Record 1: Email: john.doe@example.com, Phone: 555-1234
Record 2: Email: john.doe@example.com, Phone: 555-5678
If you set the merging rule for the "Phone" property to "Combine values," the merged record will look like this:
Merged Record: Email: john.doe@example.com, Phone: 555-1234;555-5678
Step 3: Configure the Master Item rule
When you merge duplicates, Datablist picks one record to be the main one, and the information from the other duplicates will be combined into it.
You can control how Datablist selects this Master Record by choosing from several rules:
- Most Complete: Picks the record with the most populated fields.
- Last Updated: Picks the most recently modified record.
- First Created: Picks the oldest record based on the creation date.
- Highest Value: Picks the record with the highest value for a selected property. If multiple records have the same value, it selects the most recent one.
- Lowest Value: Picks the record with the lowest value for a selected property. If multiple records have the same value, it selects the most recent one.
- Matching Value: Picks the record that contains a specific value in a selected property. If no record matches, they won’t be merged.
Step 4: Auto-Merge Duplicates (When Possible)
Each time you change your merging settings, click on "Refresh Preview" to see how the changes will be applied.

Once you've set up your merging rules, Datablist will be able to automatically merge the duplicate groups when there is no longer conflicting values.

Look for an "Auto-merge when possible" to merge them.
Step 5: Manually Merge Remaining Duplicates
For duplicate groups where there are conflicting values that you need to look at, you'll need to merge them yourself.
Datablist provides a "Manual Merging Assistant" that shows you the conflicting values side-by-side so you can choose which ones to keep for the merged record.
To use the Manual Merging Assistant, just click on the button for a specific duplicate group.
You'll see the data from all the records in that group, and you can pick the values you want to keep before clicking "Merge."

Step 6: All Done! Review and Finalize
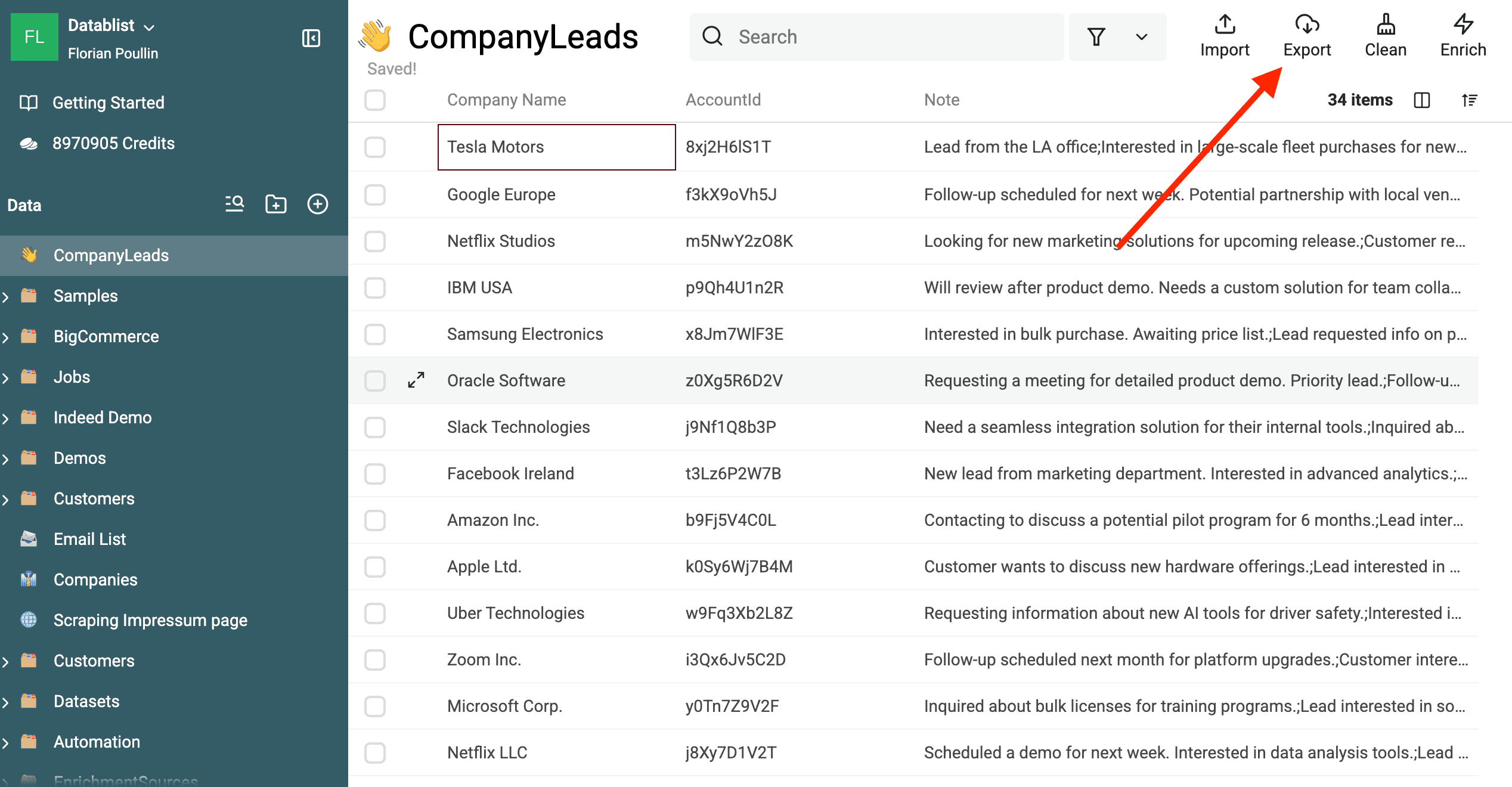
After you've merged all the duplicate groups, take a moment to look at your cleaned-up list.

Make sure the deduplication process worked the way you wanted and that your data is now accurate and free of duplicates.
Then, go back to your collection data and click on "Export" to download the CSV or Excel file with the clean data.
Try Datablist for ongoing data cleaning.
Frequently Asked Questions (FAQ)
Is Datablist really free for deduplication?
Yes! You can remove duplicates from your list online for free 💰, no signup required.
Just upload your file and start cleaning. For advanced matching algorithms, you can create a free account.
The only paid algorithms are fuzzy matching and phonetic deduplication.
Can Datablist handle large lists with thousands of records?
Absolutely! Datablist is built to process big lists efficiently.
Whether you have 10,000 or 500,000+ records, the duplicate finder will scan and group duplicates quickly. No need to split your data into small chunks—just upload and clean!
Does Datablist support fuzzy matching to catch near-duplicates?
Yes! Datablist includes **fuzzy matching algorithms 🔍 ** like Levenshtein and Jaro-Winkler to catch typos and slight differences. For example, it can match:
- "Jon Smith" with "John Smith"
- "Acme Ltd." with "Acme Inc"
You control the similarity level, so you can fine-tune the threshold for better accuracy.
Can I deduplicate my CRM contacts, leads, or customer data?
Yes! Export your CRM data (from HubSpot, Salesforce, or any other tool) as a CSV file, upload it to Datablist, and remove duplicates in minutes. After cleaning, you can use the generated Change Files to apply updates back to your CRM—no manual data entry needed!
If you use Pipedrive, we offer a direct integration for bulk deduplication.