Clean and enrich your data with ChatGPT
ChatGPT is amazing. It's cheap and it brings real value for data cleaning, segmentation, or summarisation. I'm still scratching the surface of its potential with Datablist.
In May, I added 2 new enrichments with ChatGPT: "Ask ChatGPT" and "Classification with ChatGPT".
I'm curious about how to integrate it more with Datablist. If you have ideas, please share them with me 🙂
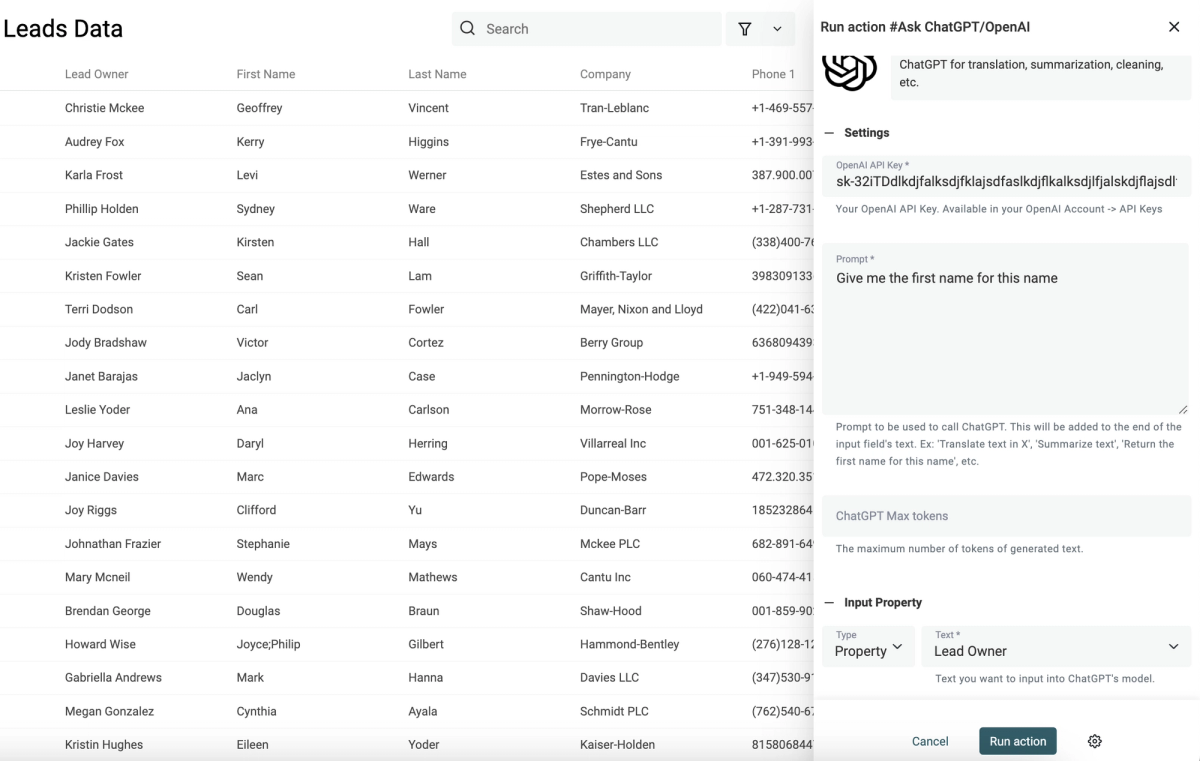
Ask ChatGPT
The "Ask ChatGPT" is simple: write a prompt and select an input property. Datablist sends a request for each of your items with a message using the prompt and the text from your item.
It uses the GPT-3.5 Turbo model and handles retries on ChatGPT rate errors.
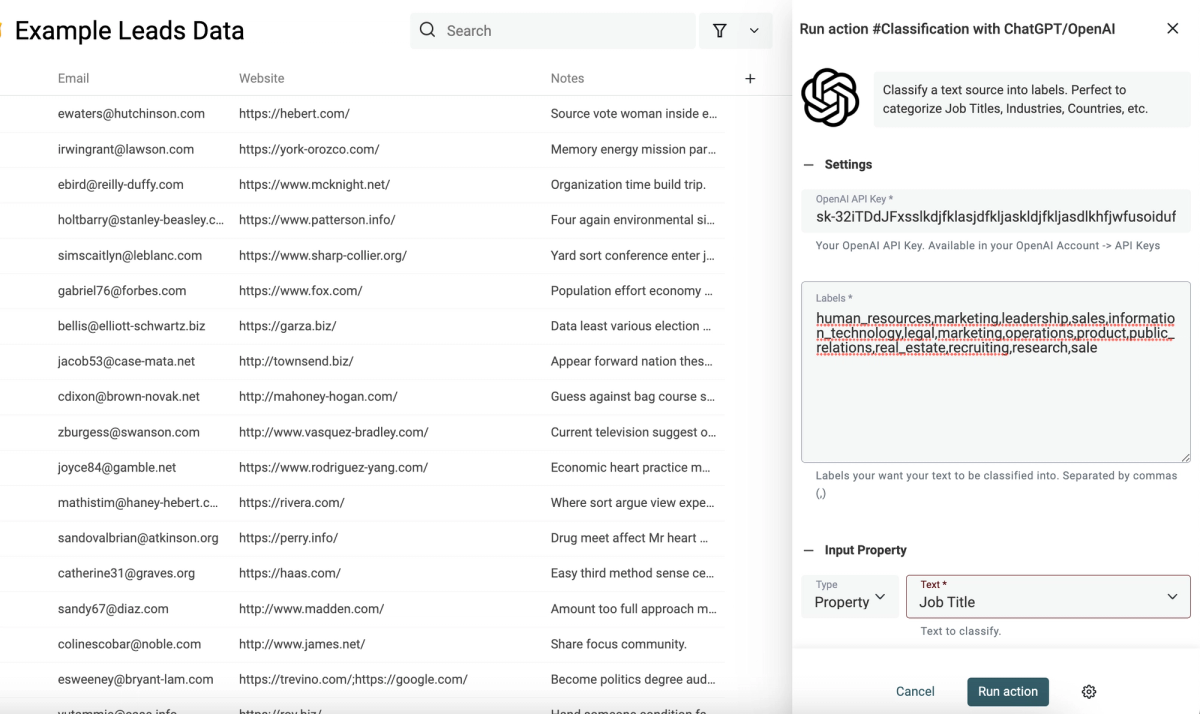
Text Classification with ChatGPT
My favorite use of ChatGPT is text classification. Given a text, ask ChatGPT to assign it to a label.
For job titles, ChatGPT performs well to segment them between tech, marketing, sales, and operation. For locations, ChatGPT can classify them between continents.
The "Classification with ChatGPT" enrichment brings two interesting improvements over the "Ask ChatGPT":
- First, you just need to write the list of labels separated with commas, and Datablist writes the prompt for you
- Second, it has a cache on top of ChatGPT. If you run it on items with the same input texts, it saves you some processing time (ChatGPT is slow), and it saves you ChatGPT tokens.
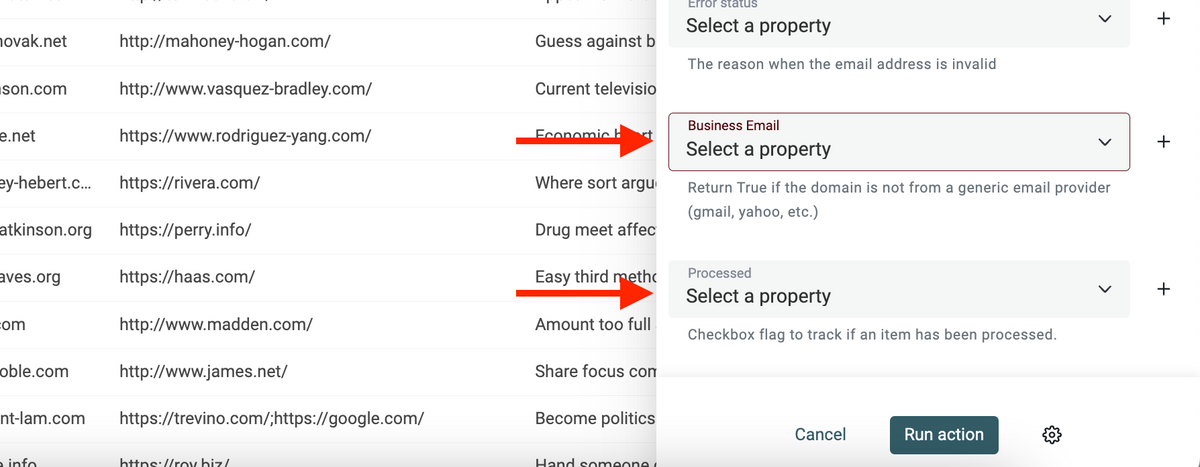
Improved Email Address Validation
In May, I worked on the Email Address Validation enrichment.
I noticed the disposable domains list was not exhaustive. I've added a lot of new temp email providers. The enrichment now compares each email domain with a list of more than 50k junk domains.
Also, I've added two new outputs data:
- Business Email - A checkbox that returns true if the email domain doesn't belong to generic email providers (such as Gmail, Yahoo, etc.)
- Processed - A checkbox that is set to true once the validation algorithm has processed the item. This is useful to filter your email list to avoid re-validating email addresses again.
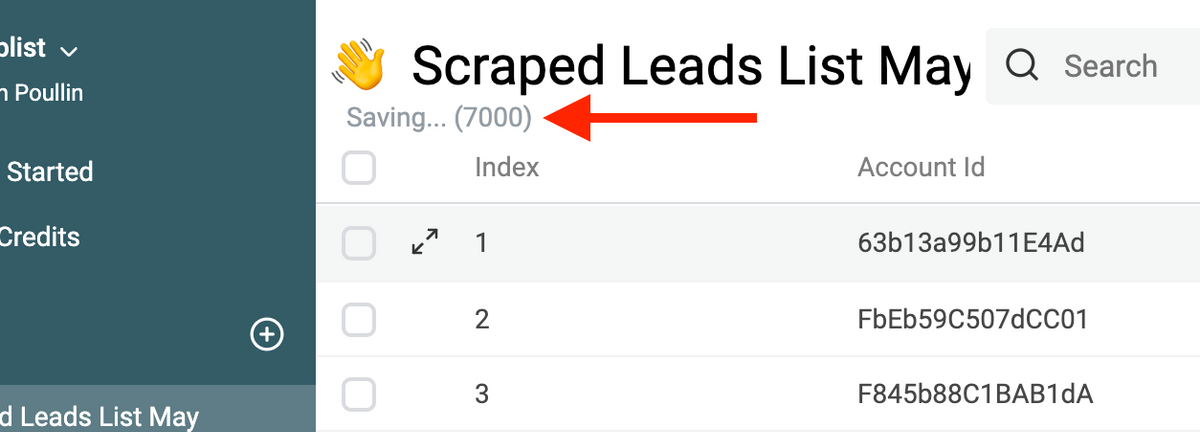
Data Synchronization Improvements
I've improved the cloud synchronization process:
- After an import, your data will be synchronized faster to Datablist Cloud API.
- The number of saved items is now visible during the synchronization with Datablist Cloud API (see image below).
- When you connect to Datablist on a new web browser, or if you are a new user, an initial synchronization occurs to fetch data from Datablist Cloud API. Before, an "empty collection" message was displayed until the end of the data fetching. On large collections, with fetching taking some time, the "empty collection" message felt not right. From now on, the collection items are refreshed directly after the first items are fetched.
- Several synchronization issues have been fixed. And conflicts saving are better handled.
- And other bugs with data syncing have been fixed.
Improvements
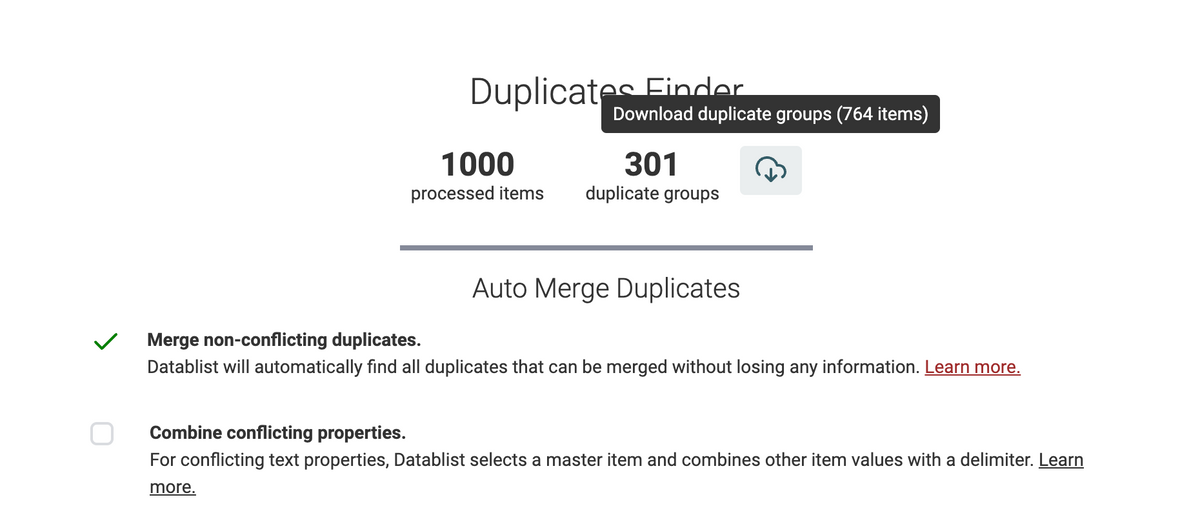
Export duplicate groups
A top requested feature: exporting the duplicate items in a CSV or Excel file!
For some use cases, removing or merging duplicates in Datablist doesn't make sense. When you want to have a list of item ids to remove them from an external system (a database, a CRM, etc.), you expect a CSV with the list of item ids to delete.
Copy data from one property to another
This is a new data manipulation action. It copies values from one property to another one with an option to prevent the copy if the destination property already contains data.
Improvements & Fixes
- On large collections, the Undo/Redo caused page crashes following a memory limit. Datablist keeps the previous data value in memory on bulk edit actions to allow undo operation. On a 1 million items collection, that means keeping the previous values for 1 million items in memory... To prevent this, the Undo/Redo manager discards old undo operations when it takes too much memory. This is not perfect. At some point, a real revision system will be implemented.
- Fix the "Export Ready" counter when exporting selected items