Fuzzy matching is a sophisticated data comparison technique used to identify similarities between strings or records, even when they're not an exact match. Unlike traditional exact matching, which requires two strings to be identical to consider them a match, fuzzy matching takes into account variations, errors, and discrepancies in the data. This makes it highly effective in scenarios where data might be slightly different due to typos, abbreviations, misspellings, or other inconsistencies.
How does Fuzzy Matching Work?
Fuzzy matching employs distance algorithms to compute a similarity score between two strings. This score quantifies how closely the strings resemble each other. Various methods are used to calculate this score, such as Levenshtein distance, Jaro-Winkler distance, and others. These algorithms analyze the characters, their sequence, and their positions to determine the level of similarity.
How to use Fuzzy Matching for data deduplication?
Fuzzy matching is commonly used for data deduplication, where duplicate records in databases need to be identified and resolved.
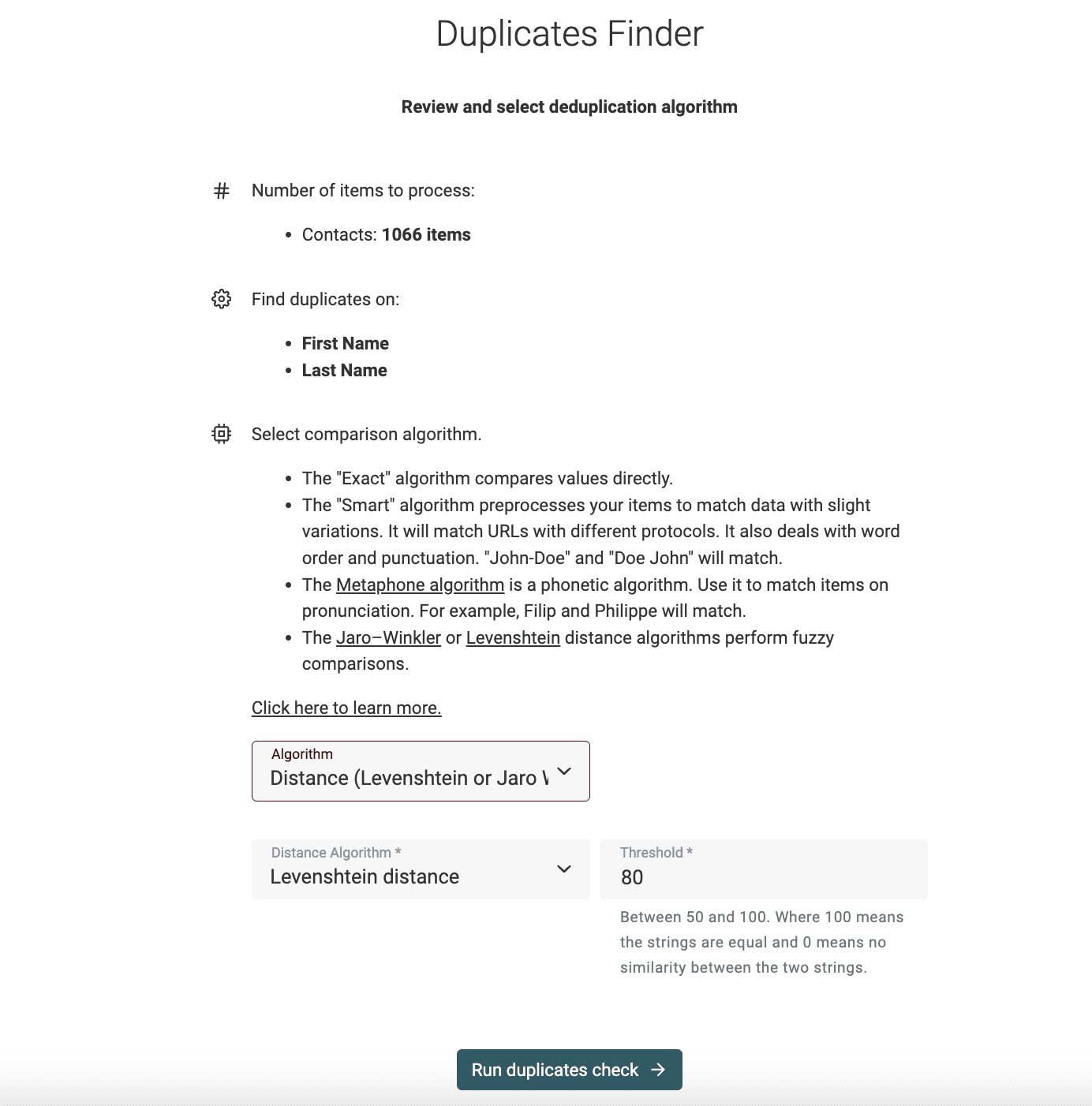
Datablist is a free data editor with powerful data-cleaning features. Datablist Duplicates Finder implements fuzzy matching algorithms to detect duplicate records across your datasets.
👉 Read our guide on CSV deduplication.